In this blog post we're going to cover the the internals and architecture behind Yrs (read: wires) - a Rust port of popular Yjs CRDT library used for building collaborative peer-to-peer applications, which now also have bindings for WebAssembly and native C interop.
But first: why would you even care? The reason is simple: Yjs is one of the most mature and so far the fastest production-grade Conflict-free Replicated Data Type project in its class. Here we're going to discuss the shared foundation and optimization techniques of both of these projects.
Document
Document is the most top-level organization unit in Yjs. It basically represents an independent key-value store, where keys are names defined by programmers, and values are so called root types: a Conflict-free Replicated Data Types (CRDTs) that serve particular purposes. We'll cover them in greater detail later on.
In Yjs every operation happens in a scope of its document: all information is stored in documents, all causality (represented by the vector clocks) is tracked on per document basis. If you want to compute or apply a delta update to synchronize two peers, this also must happen on an entire document.
Documents are using delta-state variant of CRDTs and offer a very simple 2-step protocol, which is similar to an optimization technique we discussed in the past:
- Document A sends its vector version (in Yrs it's called
StateVector) to Document B. - Based on A's state vector, B can calculate missing delta which contains only the necessary data and then send it back to A.
This way we make deltas efficient and very lightweight. Even more, Yrs encodes deltas using customized binary format, optimized specifically to make payloads small and efficient.
Under the hood, document represents all user data together with an information used for tracking causality within a dedicated collection called the block store. But before we go there, lets first explain transactions.
Transactions
A concept correlated to documents is one of a transaction - that name was inherited from Yjs and may be deceptive, as they don't have anything in common with ACID transactions known from standard databases. They are more like batches of updates reinforced with some optimization logic - like checking if updates that happen within a scope of transaction can be squashed into previously existing block store structure or triggering update events, programmers can subscribe to. These kick in upon transaction commit, which also happens automatically when the transaction is disposed.
Block store
Store is the hearth of a document. It contains all of the necessary information about updates that have happened in the scope of that document, as well as the metadata about the shape of the data types created within. At the moment Yjs/Yrs are both schemaless and to some extent also weakly typed (we'll talk about it later).
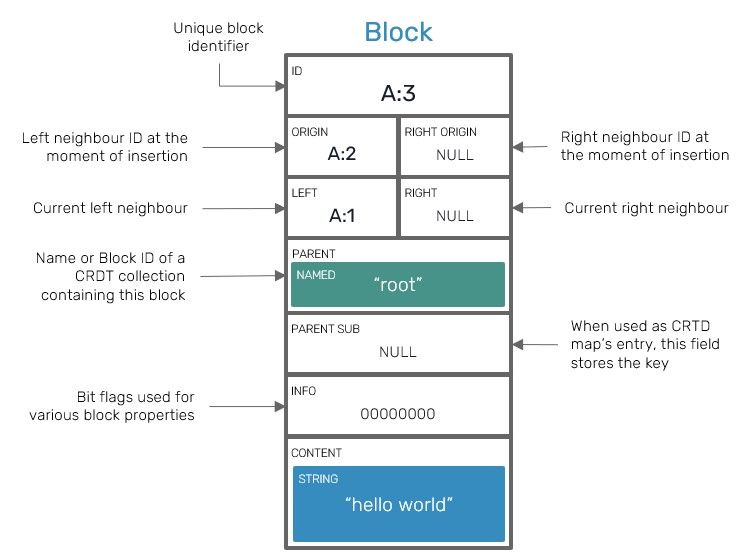
All updates in Yrs are represented as blocks (a.k.a. structs in Yjs). Whenever you're inserting or removing a piece of data into your Y-data structure - be it a YText, YArray, YMap or XML types - you're producing a block. This block contains all metadata necessary to correctly resolve potential concurrency conflicts with blocks inserted concurrently by other users:
These blocks are organized in a block store on per client (peer) basis - all blocks produced by the same client are laid out next to each other in memory:
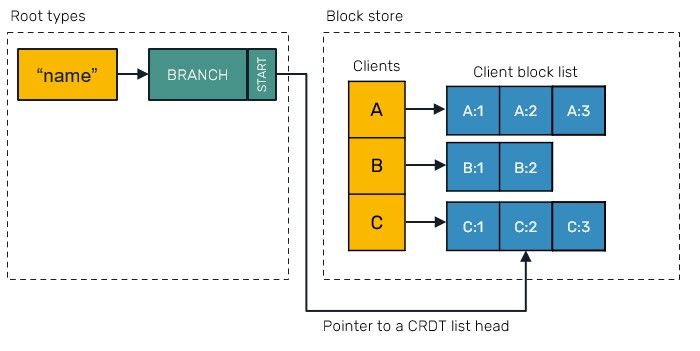
This layout is optimal to perform several operations like using state vectors and deltas, block squashing, efficient encoding format etc.
Yjs/Yrs use YATA algorithm as an universal conflict resolution strategy for all data types. We already discussed these with a sample implementation before, but only in context necessary to understand construction of indexed sequences. We'll cover how to extend this approach over to key-value maps when we'll discuss YMap design.
Each block is reinforced by a set of fields, most of which are optional:
- Unique block identifier, which is logically similar to Lamport Timestamp.
- Left and right origins which point to its neighbours IDs at the moment of insertion and are used by YATA algorithm.
- Pointers to left and right blocks - in Yjs/Yrs block sequences are organized as double-linked lists. Keep in mind that, these fields don't have to be equal to origins: origins represent neighbors at the moment of original block insertion, while these pointers represent current placement of a block in relation to others.
- Parent, which points to a shared type containing this block. In case you haven't figured out: Yjs/Yrs collection types can be nested in each other, creating a recursively nested document trees.
- In cases of map-like types (
YMapbut also attributes of XML types), it can also contain an associated key, it's responsible for, effectively working as a key-value entry. - Bit-flag field informing about various properties specific to that block data, such as information if such block has been tombstoned or what is its intended collection type.
- Content, which contains a user-defined data. It can be as simple as a JSON-like value - number, string, boolean or embedded map that doesn't expose CRDT properties, but also other nested CRDT collections.
You may think, this is a lot of metadata to hold for every single character inserted by the user. That would be right, however Yjs implements an optimization technique that allows us to squash blocks inserted or deleted one after another, effectively reducing their count while keeping all guarantees in check.
Block splitting
As we mentioned in order to optimize the metadata size of a particular insert operations, we can represent multiple consecutively inserted elements into one block. This however begs for question: what happens when we want to insert a new value in between elements stored under the same block? This is where a block splitting comes to work.
We already discussed in detail how to implement a block-wise variant or RGA CRDT on this blog post, and it's YATA equivalent is not that much different. The tl;dr explanation is: whenever we want to make a new insert in between elements grouped under the same block, we split that block in two parts and rewire their left and right neighbour pointers to a newly inserted block.
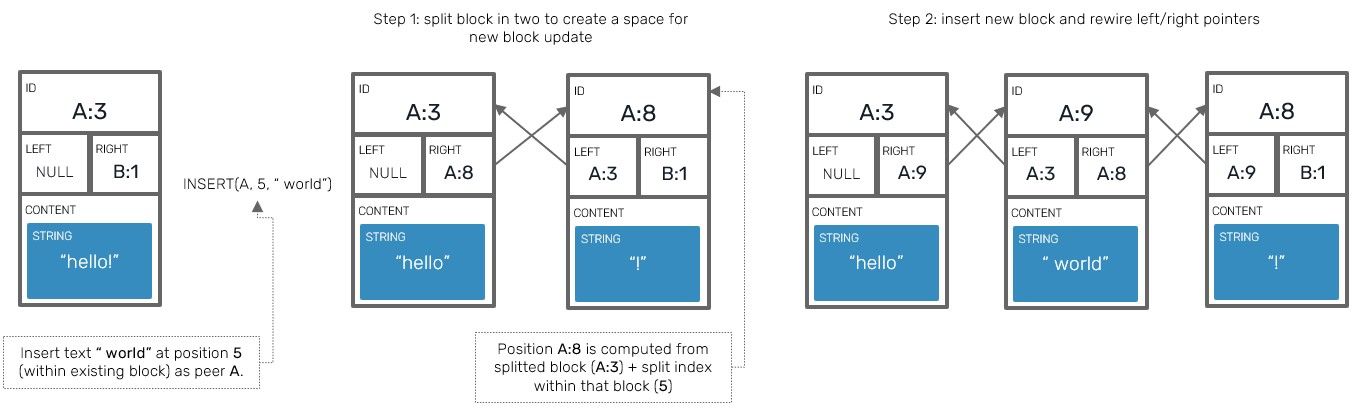
All of this is possible because consecutive block ID (client_id-clock pairs) are not assigned using clock numbers increased by one per block, but by one per a block element eg. if we assigned an ID A:1 to a 3-element block [a,b,c] and then insert a next element d on the same client, that inserted block's ID will be A:4 (it's increased by the number of elements stored in the previous block). By the same rule whenever we need to split block A:1=[a,b,c], because we want to insert another element between b and c, we can create two blocks A:1=[a,b] and A:3=[c]. These blocks representations are logically equivalent within a document structure.
Block squashing
Given the example above we can easily explain process of squashing (name is borrowed from a similar concept used by Git): it's a reverse of splitting, executed upon transaction commit. It's very useful in scenarios when the same peer inserts multiple elements one after another as a separate operations. The most obvious case of this is simply writing sentences character by character in your text editor.
Thanks to block squashing, we can represent separate consecutive blocks of data (eg. A:1=[a] followed by A:2=[b]) using a single block instead (A:1=[a,b]).
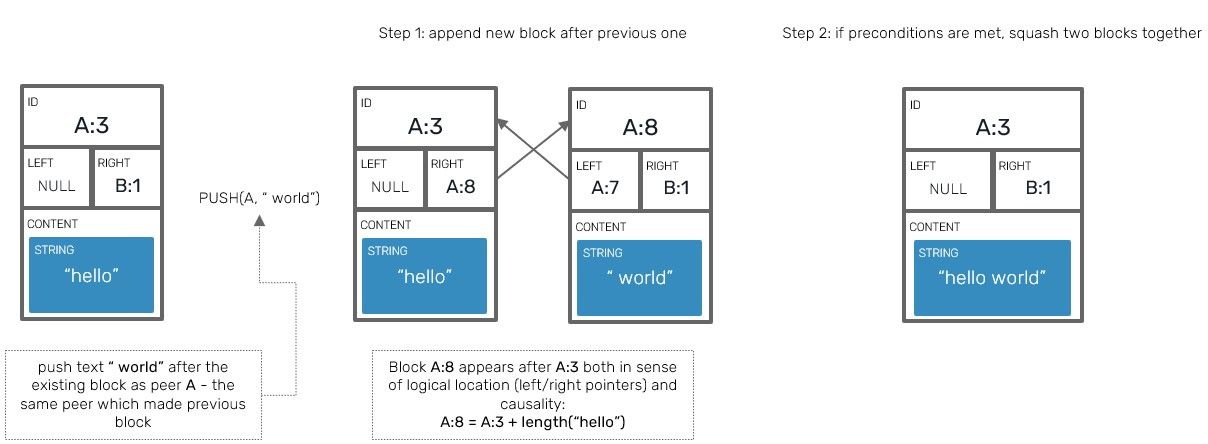
The major advantage is reduction of memory footprint (blocks contain extra metadata that can easily outweigh a small content footprint) and better memory locality (blocks are organized as double linked list nodes, while contents of individual block form continuous array of elements placed next to each other in memory).
Keep in mind that squashing has some limits to it: squashed blocks must be next to each other both in terms of A) being each others neighbours B) emitted by the same client and C) their IDs must follow one another with no "holes between" (eg. we can potentially squash A:1=[a,b] with A:3=[c], but not with A:4=[c] because we would miss some block with ID A:3 in between). Both blocks must also contain data of the same, splittable type.
Shared types
Another group of types supported by Yrs are so called shared types, which represent collections capable of having CRDT semantics. Yrs uses delta-state approach to CRDTs with an extremely small and robust replication protocol. Currently there are several types of these:
TextandXmlTextspecializing in supporting collaborative text editing.Arrayused as index-ordered sequence of elements.Mapused as key-value hash map with last-write-wins semantics (for a quite specific definition of "last" which we'll cover later).XmlElementwhich works as an XML node capable of having key-value string attributes as well as other nodes in user-specified order: either otherXmlElements orXmlText.
These types can be nested in each other according to their limitations. Unlike primitive values they can also be assigned to the document itself (using their unique names for retrieval) and obtained right from it. Shared objects created straight at the document level are called a root level types and have a very interesting characteristic - their actual type is only a suggestion on how to present their content. What does it mean and how does it work?
Underneath all CRDT collections are represented by the same kind of block content known as a Branch. Branch node is capable of storing two specific types of collections at once: both key-value entries and index-ordered double-linked list containing batches of items.
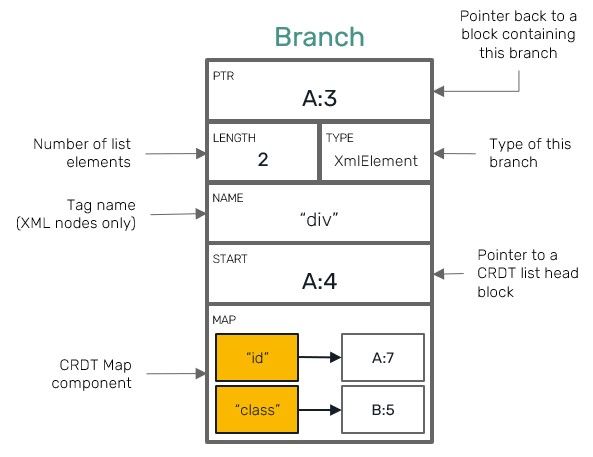
These two capabilities define a common operations, which then can be used to represent more specific traits of each type, eg.:
Text/XmlTextuse indexed sequence component of branch to build a list of text chunks. Callingto_stringoperation on these types simply glues these separate chunks of text together into a single coherent string object.Arrayuses the same chunks to store any kind of arbitrary data items (you could think about text chunks as batches of individual characters, each one being a separate item).Mapuses only key-value entry component to store values of any type, be it a primitive or another CRDT collection.XmlElementuses key-value entries to store its attributes, and sequence component of aBranchnode to contain nested XML nodes. AdditionallyXmlTextis also capable of storing attributes - it's the main difference from standardTextfield - which can be then used by specific text editors to store information used for eg. text formatting.
This structure also enables to reinterpret root-level types eg. you can read a Text as an Array (to change its materialized type to a list of characters) or XmlElement as a Map (and be able to read only its attributes). Just like with any other kind of weakly typed systems you should use these capabilities with caution.
YText and YArray
We already mentioned, how Yrs Text and Array types make use of the same indexed sequence component and their in-memory representation is basically a double linked list of continuous elements (such as individual string characters or ranges of JSON values).
Thanks to the use of YATA conflict resolution algorithm, these types are free from interleaving issues boggling other CRDT algorithms like LSeq. And since we're using split-block approach, it lets our insert operations computational complexity to become independent of the number of elements inserted (in most cases). In practice this means, that operations like text copy-paste always have complexity of O(1) no matter of the number of characters to insert. Sounds obvious, but atm. it's still not a standard in many other CRDT implementations you could find out there.
YMap
So far we only mentioned, that all branch nodes are by their nature capable of storing key-value data using Last Write Wins™ semantic. How does it work? Initial premise is simple - all branch nodes literally have special "map" field, which contains hashmap of entries, each of them being a string key and pointer to the last block (all Yrs values are stored in blocks) containing a corresponding value.
Now, whenever we override that value by another insert under the same key, we attach a new data as the right-most neighbour of the previously written block, point to it from now on, and tombstone all blocks on the left side of it, including a previous entry's value.
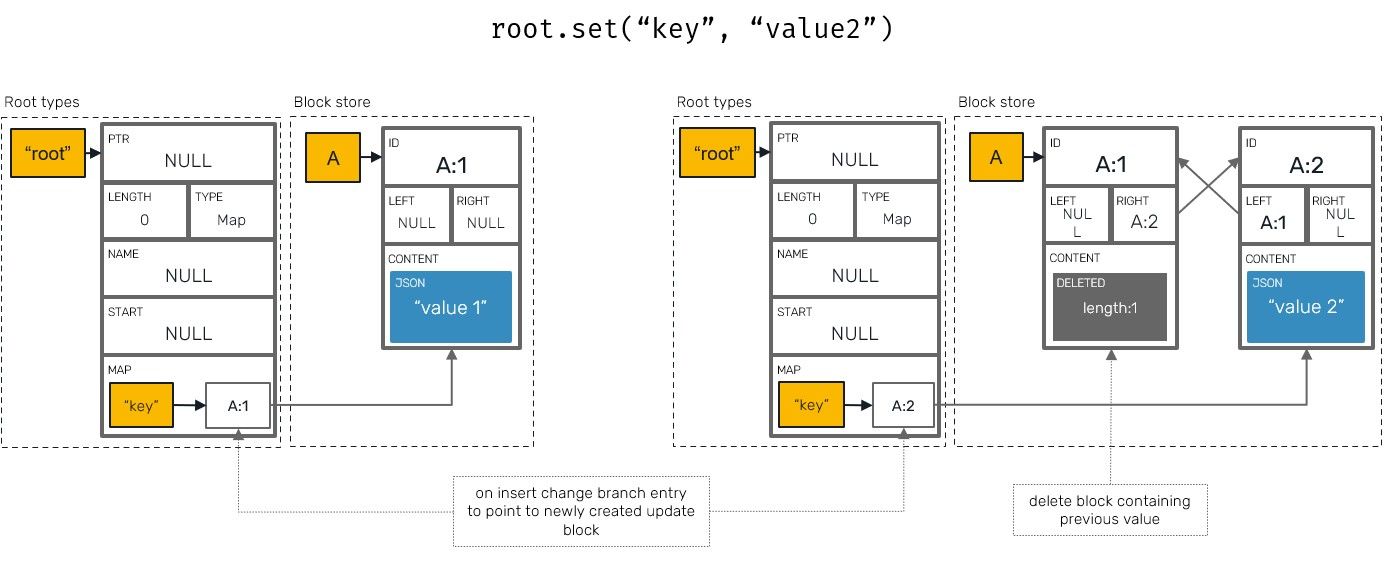
This is what we mean by "Last Write Wins": instead of using client system clock on the peer machines we use the same principles that YATTA algorithm offers to order text insertions. In this context last means "the block with the highest client ID and clock value".
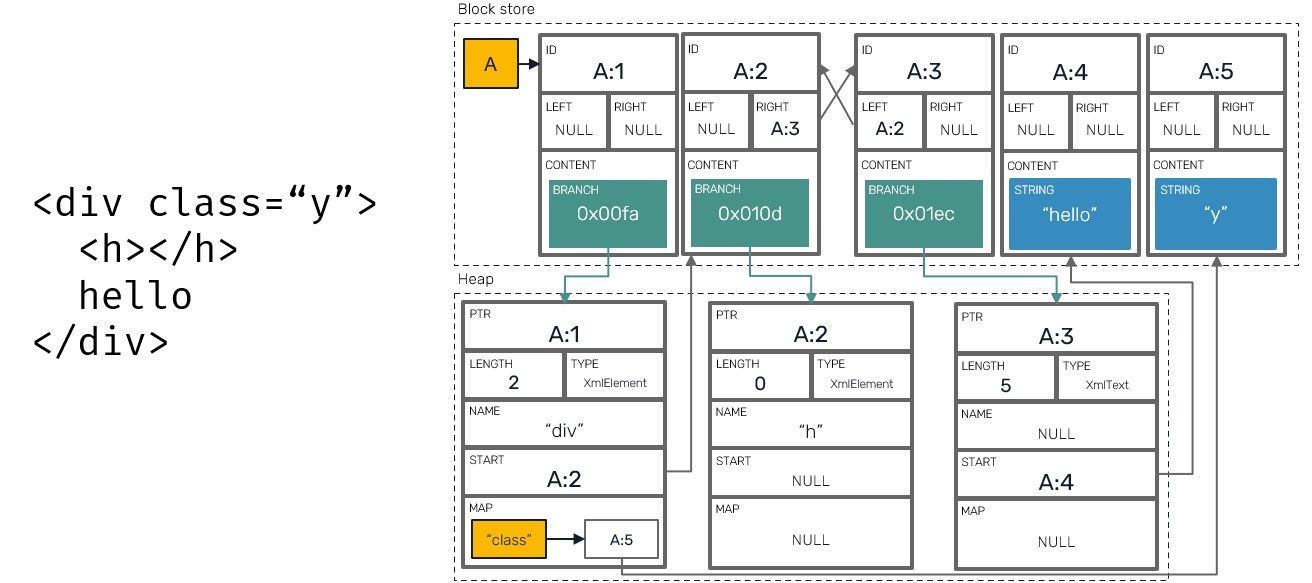
Xml types
One of the things, that Yrs is also capable of, is a conflict-free support for XML representation. What we mean by that is a dynamic nested XML tree of nodes, which can contain attributes, text or other nodes. The way it works is actually pretty simple: a branch node uses its list head to point to a first XML child node block and map field to point to blocks used as attributes.
Serialization
Both Yjs and Yrs use the same very efficient data exchange format, which means that we can achieve backward compatibility with systems already using Yjs. It exists in two versions:
- v1 encoding relies heavily on variable integer encoding and block store layout to omit fields which can be inferred using blocks mutual relationships.
- v2 encoding was influenced by research made by Martin Kleppmann when he worked on automerge library, and adapted to Yjs. It extends the formatting to make use of run-length encoding, which can bring further savings, especially for deltas having many block updates.
Note: before moving on let's make quick recap of what varint encoding is all about - it allows us to save space when encoding integer values that usually take many bytes (like 4B and 8B integers) by getting rid of empty bytes. It's especially useful when stored integer values are small ie. string length or Lamport clock values.
Here, we'll cover only v1 encoding. To do so, let's use some sample:
use yrs::Doc;
let mut doc = Doc::new();
let mut txn = doc.transact();
let ytext = txn.get_text("name");
ytext.push(&mut txn, "def");
ytext.insert(&mut txn, 0, "abc");
ytext.remove_range(&mut txn, 5, 1);
txn.commit();
let delta = txn.encode_update_v1();
This could produce following payload:

which further we could translate into something that resembles document store represented below:
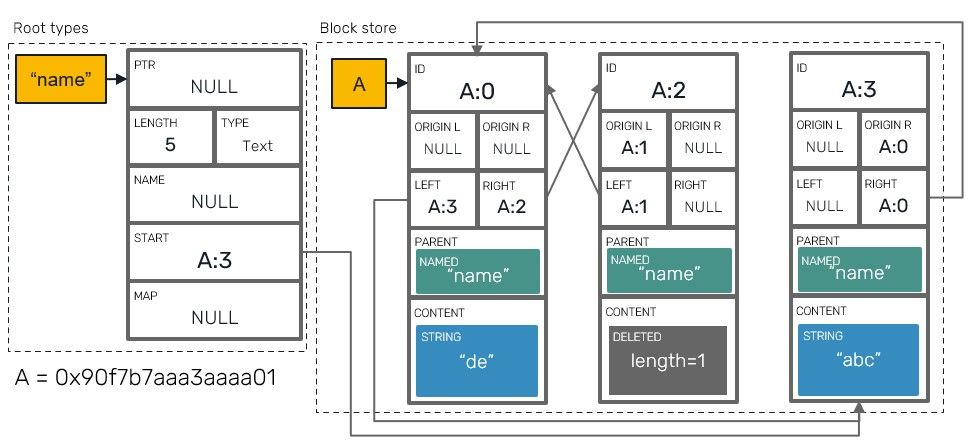
We can make several observations here:
- We try to deduplicate fields as much as possible:
- Block IDs are inferred based on start clock and length of previous block. Block ID's client field is also specified only once for all blocks sharing it.
- Parent field is not repeated for every block, instead during decoding it will be inferred from linked neighbor blocks.
- Some things like client IDs cannot be deduplicated by v1 encoding. In fact client IDs make up a big chunk of our delta payload seen above. It's because when using
Doc::new()we're using a randomly generated numbers as client ids. If you're into byte-shaving business, you can assign small client ids manually by callingDoc::with_client_id(id)instead and let varint encoding compress bytes - this way we could even go down from 58B → 30B payload. However in such case you're responsible for keeping these IDs globally unique. - We use bit flag bytes to specify type of content stored in each block. We also utilize remaining bit positions to inform which fields are present (eg. left/right origins used above). This way we don't need to loose extra bytes to mark fields that were null.
- As you may have noticed the delta payload doesn't even explicitly mention root types: their presence and identifiers are instead inferred directly from the block data.
- In example above we keep information about tombstoned elements using both delete set and block with deleted content. It's because delete set propagation is mandatory, while blocks are encoded only if they were not observed by remote peers. It was the case here, but in reality it's not so frequent.
Using customized format we can make advantage of our knowledge about the domain of problem rather than relying on some generic serializer. This allows us to optimize payload size to a point, that wouldn't be possible otherwise.
Delete Set
We already mentioned Delete Sets, when we talked about YATA algorithm itself, but haven't covered it here. In short it's a collection of deleted ranges of block elements grouped by each block client ID:
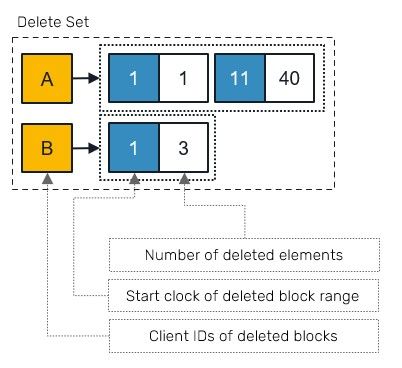
Unlike in the case of Rust Range<u32> we use pair (start, length) rather than (start,end) since this gives us a chance for more compact representation when using varint encoding. Delete sets are mostly used as a serialization-time concepts. They are rarely present in the block store during normal updates and their state can be derived by traversing the document store itself.
With this approach we can inform about hundreds of removed elements at a cost of just few bytes.
Summary
With all the details described here I hope, you'll find this topic interesting. If you want to dive even more, feel free to take a look at Yrs repository. Here we only shared a top-level overview of the architecture, as it's the least likely to change but is still useful when trying to navigate over the code base.
We're still in the very early stages of the project and we're only just started our long way on optimizing the internals to take full advantage of the capabilities of Rust programming language - for these reasons keep a watchful eye on the version numbers in the benchmarks you might encounter ;)
Comments