Today we'll explain how do modern databases allow us to perform backups without blocking - thus enabling users to operate on them while the backup is beign made continuously in the background. We'll also show how this approach allow us to restore database to any point in past.
While there's no single universal tool to complete these tasks - each database is different after all - we'll use a Litestream (a Go backup tool working over SQLite) as a point of reference when going into the practical details, but we'll also cover different techniques and optimizations that could have been made and applied not only to SQLite but other databases as well.
How do databases manage data on disk?
If we're about to backup our database we first need to understand how it manages the data in the persistent memory (disk). Most of the existing databases use either B+Tree or LSM data structures to persist data. Here we'll focus of B+Trees - since all of the most popular SQL database implementation use this approach - but what we're going to talk about is also applicable to most Log Structured Merge trees.
The basic persistence unit of a B+Tree is called page. Pages are organized into tree structure with a root page usually being stored at the beginning of a database file. It typically has a metadata required to recursivelly navigate over pages to access the rest of the tree's nodes, as well as recycle released pages for future reuse.
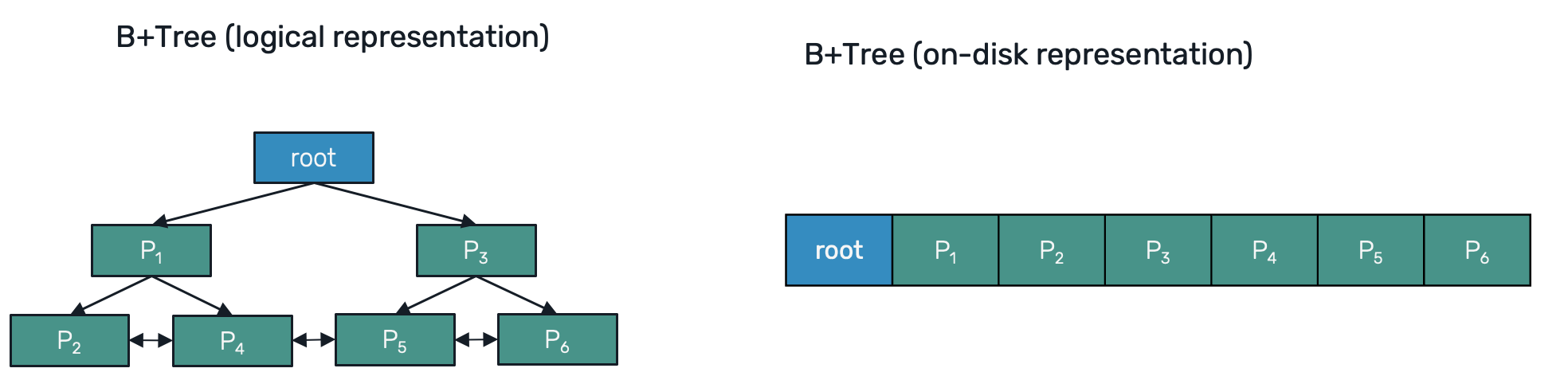
All pages have the same size, which allows us to quickly lookup for them on the disk. For SQL databases like Postgres, SQLServer or Oracle, this page size is fixed and set to 8KiB. Since SQLite is used in variety of environments (from server-side hosting like Turso to embedded devices and even malware), the page size is configurable, between 512B and 64KiB, with 4KiB as a default.
Write-ahead Log
Whenever a SQLite is about to insert or modify a record it's first creating a copy of an entire page containing that record. This happens always, no matter how small the change is. It means that even if you're about to modify just a single bit, SQLite will still copy full page.
Now, currently pages in SQLite are managed in one of two ways:
- Rollback Journal - used by default - where the previous (unchanged) version of the page is stored in a separate rollback journal file, then the target page in a database file is modified. If process fails abruptly, upon opening SQLite again, restore process will override all uncommitted modified pages in a database file back with their previous versions from the journal.
- Write-ahead Log works in reverse to rollback journal. The modified page version is stored in a side file - the log - in an append only fashion. SQLite now keeps index of pages, which are now split between database file and write-ahead log (WAL). Once in a while, during so called checkpoint process, all committed pages stored in WAL are replacing their previous versions in a database file. Once a WAL file has been sucessfully applied, it can be truncated. If process did die and database has to be restored, we can simply invoke checkpoint to fix database into its most actual state.
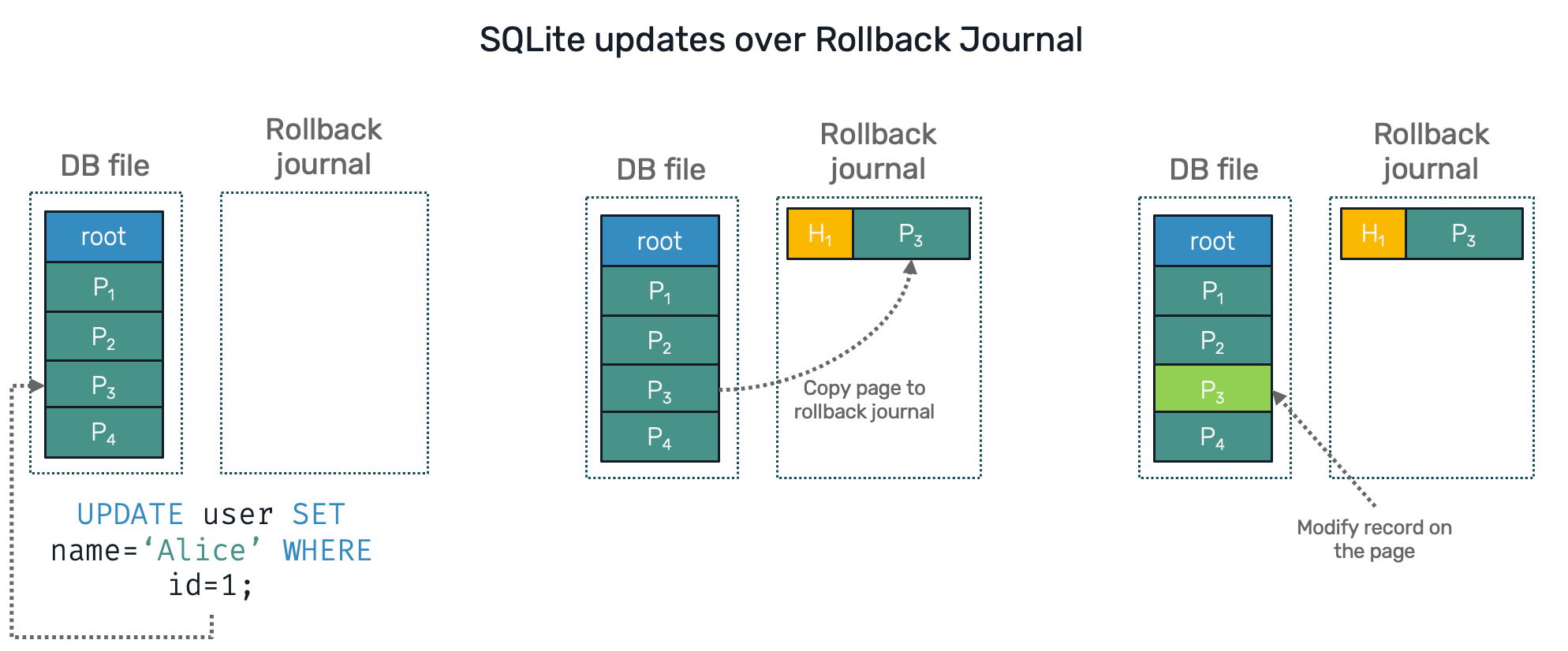
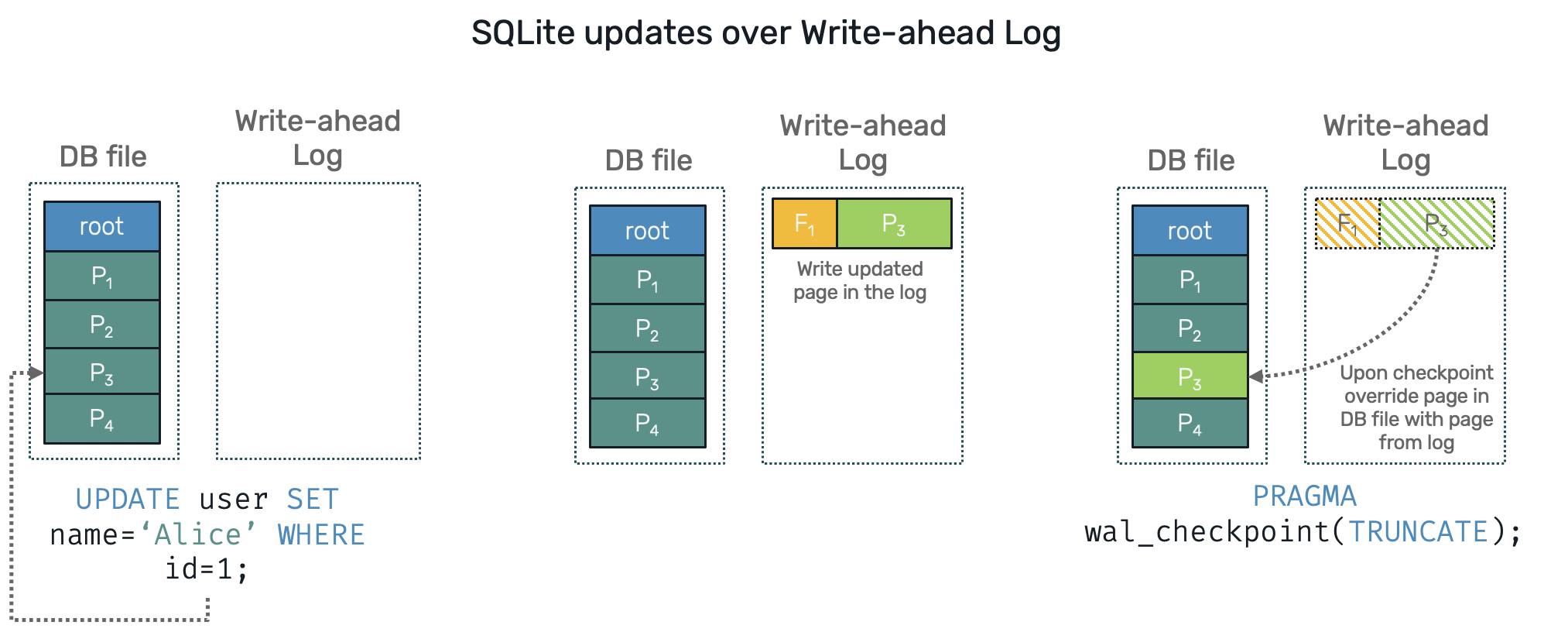
For our purposes, we're going to use write-ahead log (your can turn it on by simply calling PRAGMA journal_mode=WAL; on newly opened SQLite database). In a sense this approach is very similar to event-sourcing, but applied on a database level. It's very practical, as the log file allows us to track all changes on the database by simply scanning it over. This property is also used by tools for change data capture (CDC): Debezium working on Postgres is one of them.
Write-ahead log also allow us to easily recreate the database state by simply flushing all changes - assuming they are well structured - to a WAL file and requesting SQLite for a checkpoint. Can you see already where are we going?
Backing up the WAL
Old fashioned database backups were just about copying a database file/folder aside. This usually required a period of technical break, during which operators had to guarantee that the copied files won't be changed, as this would compromise database integrity. Therefore all services using it had to be stopped or would work at limited capabilities.
With the theory above we can now envision our backup process - all we need is a initial copy of a database file, followed by continuous copying fragments of growing write-ahead log. Since WAL is append-only by definition, we can safely read from it without locking the file itself. The only periods, where an existing database file changes and WAL gets truncated, are during checkpoint calls. However SQLite has well defined rules when that happens:
- It won't truncate WAL file, if there are other transactions open at the same time. It means, that if our backup service keeps an open transaction, it can prevent undesired file changes from happening. This is exactly how most tools like Litestream operate.
- Additionally SQLite doesn't try to checkpoint on every transaction. Checkpoints imply random lookups on database file in order to find location of the pages to be overriden. And random file lookups take longer than sequential disk access provided by WAL. Therefore auto-checkpoint will first wait for a sufficient number of pages (1000 by default) to be appended to WAL before calling for checkpoint. This lets us amortize latency caused by disk writes, as write operation can return right after sequential write to WAL is complete.
Additionally we don't want to backup every new single page that we notice appearing in WAL file. First if process is killed before transaction is committed, we don't apply its changes - doing so would violate ACID guarantees of transaction and potentially treaten the data consistency. Additionally we can easily imagine scenario, where some write-heavy changes are done within a transaction scope simply to be rolled back at the end. We don't need backup of pages that are simply going to be discarded anyway.
In order to be concious about what are we backing up, we need a bit better understanding of WAL file structure. It's not that complicated: every WAL file starts with a 32B header followed by pages prefixed by 24B frame headers (within a WAL we use use term frame to describe page with an extra metadata header required to apply that page later during checkpoint).
Most important for us is the 4th byte offset, where we have a field used for defining a commit transaction frame. Anything other than 0 means, it's the last frame of the transaction and all frames up to this point can be safelly applied (or backed up). Since atm. SQLite allows only a single writer transaction at the time, we can easily backup the WAL by reading WAL file segments from one commit frame offset to another. Keep in mind that checkpoint may cause WAL file to be truncated, therefore causing read offsets to go back. Once we determined a log file segment that's safe to be copied to backup volume, there are few more decisions to be made.
Usually uploading the segment straight from WAL file over to the network drive (or cloud) is not a good idea. There's a significant latency difference between writing to a local disk (microseconds) and a datacenter which can exists possibly on another continent (up to hundreds of milliseconds). By backing up data straight from the WAL file, we prevent it from making changes, moving that latency onto the database checkpoint process and transaction commit latencies. It's better to store a backup segment aside on the same drive first and then upload it asynchronously, possibly in parallel - at a risk of having incomplete fragmented WAL backup in case of abrupt failures.
As we mentioned before, each change - no matter how small - means creating new page. Since backup itself doesn't need to access contents of individual pages, it's good to compress them prior to backup. Litestream uses LZ4, which is very fast but has also not perfect compression ratio. Algorithms like zstd and xz seem to have very good output file size for a data patterns used by SQLite pages.
Generations
If you worked with Litestream, you've might noticed the concept called generations. Initially it may sound unfamiliar as it's not related to existing terminology used commonly in databases. Generations could roughly map onto active process sessions. It's important for few reasons:
- There might be several processes restored from a given write-ahead log backup running at the same time (intentionally or not). If they do, they may interfere with each others WAL segments, corrupting our backup, thus making it unrecoverable.
- If we're about to do a point-in-time database recovery to some past state, we don't want to override more recent data - we still might need it in the future.
Therefore, we want to be able to cut a lifetime of our database into some periods of continuous single-process activity. Since we know that during that period database write-ahead log represents a complete sequential history of changes, we may feel safe about restoring it. These periods doesn't necessarily need to map 1-1 onto process activity time - they might be also ie. periods from one checkpoint to another, as during that process the WAL itself changes.
These generations are build in the parent→child relationships and they can potentially branch - as explained in the points above - into different versions of the database. It might feel similar to how Git branch history looks like, but unless we figure out some way to reconcile conflicting updates, there's no way to merge two branching generations together.
For practical reasons generations are given unique identifiers that compose into descending creation order. This way the most recent generations - which are the most likely to be used for recovery - are faster for sequential reads in the most popular blob storage services like S3. For such cases UUID in version 7 offers timestamp-prefixed unique identifier construction.
Point-in-time recovery
Once we discussed WAL file backups, let's go over the recovery process. In simplest terms, the recovery is just downloading and unpacking the WAL segments into an artificial WAL file and then calling for the checkpoint (ie. PRAGMA wal_checkpoint(TRUNCATE);) until we roll the entire backup on top of a database file. This process may be time consuming, and we'll talk about how to optimize it in a second.
Now, let's discuss how to use the WAL-based recovery to achieve point-in-time recovery. This depends on few factors:
- All generations have timestamp-based UUIDs, therefore recovery first needs to identify generation that contains the timestamp we're interested in.
- When genrating a WAL segment backups, we also need to generate identifiers for them. Usually this is a combinations range of frame numbers (that will let us figure out if there are no missing WAL frames in the backup ie. because some segment file was not uploaded or it was deleted). For point-in-time recovery, we also include a timestamp as a part of that identiifer. This way we can simply decide what's the most recent WAL segment prior out expected restoration time.
In case of Litestream the WAL segments are gathered on time interval basis, which by default is every 10s. This is the precision of recovery time you can count on.
Snapshots
As you might have noticed, restoring database state from the full history of changes recorded in WAL may be time consuming. Additionally it also requires us to store the whole history forever, which over time may get pretty expensive.
One of the popular techniques - also present in event sourcing - is creating periodic (ie. once a day) snapshots of the database. This means basically restoring a database at a given point in time in a side process (which also lets us double check if our backup works and hasn't been corrupted), then compressing and uploading the restored database file. Before compressing a snapshot you can also consider calling a VACUUM of the database file to cleanup free pages - this can significantly reduce database file size in situation where there are a big spikes of inserted then deleted data.
During the restoration process we additionally lookup first for the most recent snapshot to a time we're interested in.
With snapshots in our hands, we can remove the WAL backup prior to a given snapshots and still being able to recover. This retention period usually lags behind most recent snapshot, eg. while snapshots are done every day, we still want to be able to recover up to one week prior. Another option is to move older backup data onto different eg. cheaper but slower, storage service.
A friends advice: snapshots should be done asynchronously and possibly not on the same machine where the database itself operates. The reason is that this process may consume a lot of resources - potentially doubling the disk space requiremets or occupying CPU for the compression and I/O on moving a large database file - thus hinder the database performance itself. Litestream uses an explicit CLI command for snapshotting, so it can be turned to be performed periodically.
Deltas
Let's now cover some of the ideas, where Litestream couldn't take us.
While snapshotting is a useful thing, it comes at the cost: we're unilaterally compress a whole file, no matter how much of the data set has actually changed since previous snapshot. On the other hand WAL may also represent a huge churn, with a lot of frames generated but actually a very few records changed in the greater time scale. This happens when we have a lot of updates but few inserts: continuous modifications of the same record cause massive flood of new WAL frames onto a disk even though they all may change the same database page.
If we consider our WAL segments in a bigger time window we may notice that from recovery point of view all that matters is just replaying the most up-to-date version of a given page, without all of the intermediate frames created along the way. This means that we could collect all WAL segment backups generated over the span of ie. 1h and squash them together, leaving only a delta of the most recent page versions updated within that hour.
Moreover this approach can be applied recursivelly as well - building 2nd, 3rd .. level deltas for a bigger time frames out of the lower-level deltas. In such case restoration is done by appling the highest level deltas first (as they cover the biggest time periods), then gradually comming down to lower-level deltas until we must replay the final steps stored in original WAL segments we backed up. This way we can greatly speed up the restoration process while still keeping the promise of granular point-in-time recovery.
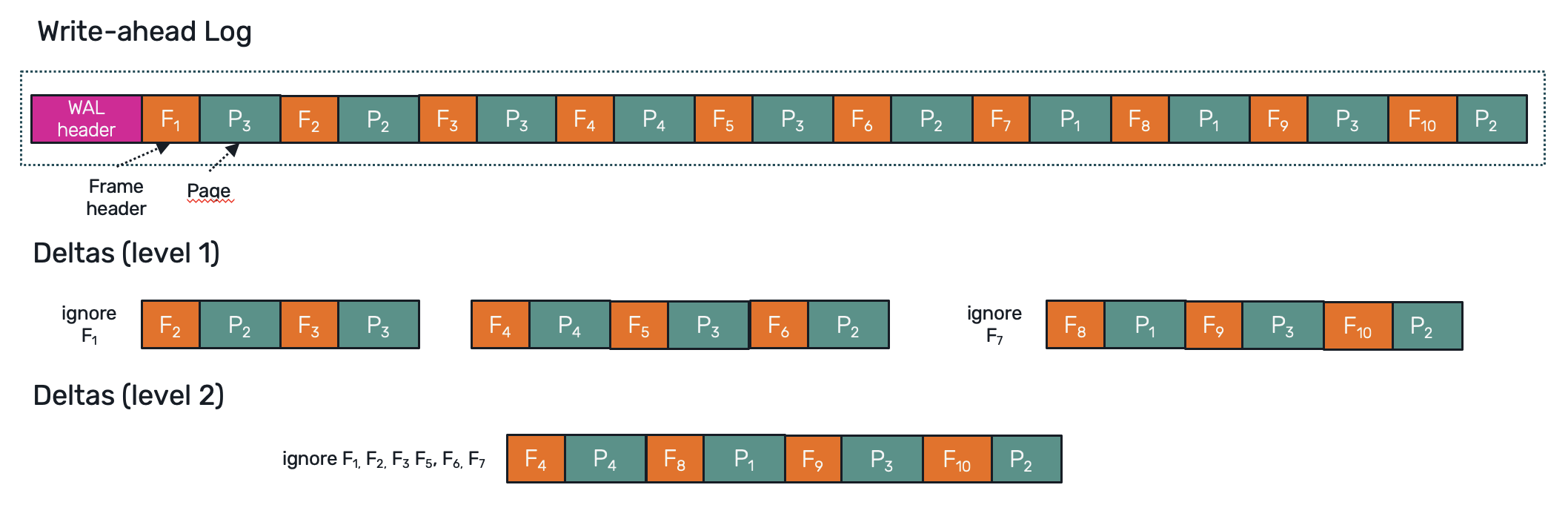
It's easy to tell that this approach comes together with some complexity issues. We need to figure out how to artificially produce WAL file headers and frame headers, which requires to generate SQLite compatible checksums (as they rely not only of the content of an individual page but also on the checksum of previous frame). Alternativelly we can skip SQLite checkpoint process altogether. Since the first 4 bytes in each WAL frame header is just a page number, we can identifiy which part of a database file to overwrite by ourselves. SQLite also offers an integrity check function to verify if we didn't broke anything during that process.
Keep in mind that deltas can be - just like snapshots - constructed in a separate asynchronous process. However they are a way of speeding up the recovery process, not a means to replace snapshots. We could use them to take advantage of snapshotting process: instead of snapshotting in arbitrary time intervals, do so ie. when deltas start covering too many pages - the advantages of deltas are degrading as a total coverage of a database pages grows.
Backup log as database replication tool
As we covered the concept of write-ahead log based backup, there's another idea also strictly related to principles of a log: a database replication. Many distributed systems and protocols (ie. Raft) synchronize their state changes by appending them to a dedicated append-only log and replicating it over all member processes. While some of them like rqlite have their own way of logging statements and replicating them, it's perfectly possible to replicate WAL fragments just like we did when producing a backup.
It could be even possible to replicate the database via WAL backup, however it comes with some incentives which may be different between replicating WAL for cluster and backup purposes: WAL upload is usually lagging behind the actual operations done over the database instance, however since it's done asynchrously (in case of backup service), it's not affecting the database response times.
Contrary, many self-organizing cluster protocols like Raft require confirmation of at least majority of the members that the data has been received before confirming the operation. The challenge is that the WAL replication process cannot be detached and its performance - affected by things like frame compression and upload - may now affect latency.
Advantage is that since backup storage is passive element of the system, it's often easier to manage and allows us to separate storage from the compute, which brings us to our last point...
Final note - serverless databases
We covered the basics of backup/restore process by using the write-ahead log, but this is not where the story ends.
Additionally an idea of continuously storing database state in 3rd-party storage like Amazon S3 or Azure Blobs can be further explored into a space of serverless databases - the term introduced together with Amazon Aurora and further developed by products such as Neon, Nile (for PostgreSQL-compatible systems) and Quickwit (for search engines).
The core principle lies in separating where the primary database data is stored and where the database process itself (the "compute") is executed. Unlike web application processes, dynamic scalling of database processes was historically a hard problem as it involves replicating (potentially large) amount od disk-persisted data to a new machines, which can be time-consuming. Serverless approach makes our databases easier to scale, as its designed from the ground up to start quickly, then fetch and cache only the required data, without need to copy gigabytes of database file before being able to serve requests. This however requires an efficient way to index and lookup for pages - which we didn't talk about here.
If you're interested about more technical details behind serverless database architecture, I'd recommend a Jack Vanlightly blog post about Neon's database for good start.
Comments