Today we're going to continue exploration of Conflict-free Replicated Data Types domain. This time we'll start designing protocols that focus on a security aspects as first class citizens.
Managing security and permissions in peer-to-peer systems may be quite cumbersome as often there's no single authority to rely on. For now let's concentrate on one thing and try to answer the question: what problems do we want to solve when we talk about authentication? We need a way to verify the identity of peer and prove that updates authored by that peer were in fact made by them.
The CRDT replication protocol we're about to implement could be put into operation-based category. We're going to use partially-ordered log of records, each representing some update authored by the peer. These records can have different order on each peer, however they will always preserve happened-before relationships between them and their predecessors.
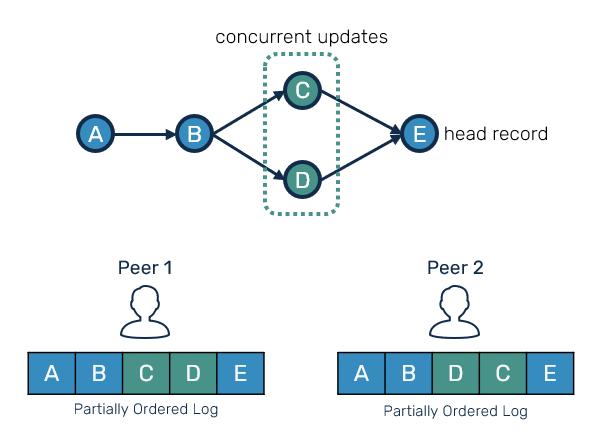
If this illustration seems familiar to what you've seen in version control systems such as Git, it's because it is. In fact for people familiar with Git, it's a good mental model to begin with as we'll be moving forward.
For user identity we're gonna use a public/private key pair - it's pretty standard approach, used in some distributed version control systems such as Pijul for the same purpose. This way peer's public key will be used as their unique identifier.
For records themselves in the past we used either vector clocks or Lamport clocks: a combination of PeerId and some incremental sequence number. This time it won't be enough. If an impostor knew the PeerId - which is public - they could forge an update and use it to corrupt the state of the system. Instead we'll use content addressing - namely each record unique identifier is a secure hash (here: SHA-256) of its content and records which happened directly before it. This way record impersonation won't be possible, as changing the content means changing the ID itself. If this triggers your geek senses and reminds you about Merkle trees, you're right - our log of records works the same way.
One of the downsides of replacing vector versions with content addressing is that we no longer can use it to track causality between one record and its predecessors. We cannot derive predecessors given the hash alone. We'll solve this by adding a deps field - a list of parent records IDs, which were the latest records in our log at the moment of committing current records. Usually this would be just a single parent (current head), however when we're having records representing concurrent updates being merged into our log, this number may change.
// Unique identifier of a Record.
type ID = [sha256.Size]byte
// Unique identifier and a public security key of a Peer.
type PeerId = [ed25519.PublicKeySize]byte
type Record struct {
id ID // globally unique content addressed SHA256 hash of current Record
author PeerId // creator of current Record
sign []byte // signature used by an author used for Record verification
deps []ID // dependencies: IDs of parents of this Record
data []byte // user data
}
func NewRecord(pub ed25519.PublicKey, priv ed25519.PrivateKey, deps []ID, data []byte) *Record {
p := &Record{
data: data,
parents: deps,
author: NewPeerId(pub),
}
p.id = p.hash()
p.sign = ed25519.Sign(priv, p.data)
return p
}
// Returns a content addressable hash of a given Record
func (r *Record) hash() ID {
h := sha256.New()
for _, d := range r.deps {
h.Write(d[:])
}
h.Write(r.data)
h.Write(r.author[:])
return NewID(h.Sum(nil))
}
If you know Git etc. well, you may notice that the resemblance becomes even more uncanny.
Partially ordered log
Next step is to define a partially ordered log. Here we'll use an in memory version for simplicity, but we'll also discuss a basics for SQLite-oriented approach.
The thing about our current approach is that once we append a record to a log we cannot really remove it - pruning could be potentially possible with stabilization approach known from pure operation-based CRDTs and its an interesting topic to cover in the future. For sake of our snippet we'll use simple slice. Since log is append-only, we don't need to worry about index changes, therefore we'll use record indexes as a sort of primary key / clustered index. Additionally we'll add two secondary indexes:
- Mapping from
RecordID to its position in a log. - List of children for each record. Originally
Recordstruct has embedded list of its parents, and this is a payload that we include during the serialization. However for the sake of convenience mapping the other way (parent→child) is also useful.
type POLog struct {
records []*Record // append-only log of records
index map[ID]int // index of ID to its index position in the log
childrenOf [][]int // for each record at related records position,
// provide a list of indexes of its children
}
Now, appending process is simple - we need to verify if record has not been forged (verify its signature) and make sure that all of its children are present. We won't append a record until all of its parents were appended before - this would cause a causality teardown. In such case we'll stash them aside in a separate structure.
func (log *POLog) Append(p *Record) error {
if err := p.Verify(); err != nil {
return err // invalid patch trying to be committed
}
if _, found := log.index[p.id]; found {
return AlreadyCommittedError // duplicate record
}
for _, dep := range p.parents {
if _, found := log.index[dep]; !found {
return DependencyNotFoundError // parent missing
}
}
i := len(log.records)
log.records = append(log.records, p)
log.index[p.id] = i
// update parent->children indexes
log.childrenOf = append(log.childrenOf, nil)
for _, dep := range p.parents {
pi := log.index[dep]
log.childrenOf[pi] = append(log.childrenOf[pi], i)
}
return nil
}
In order to navigate over the graph of records, we'll also need a way to identify parts of the graph in context of a given record(s):
- predecessors - records that must have happen before current record(s), basically their parents, grandparents etc.
- successors - records that happened after current ones, so their children, grandchildren etc.
- concurrent - neither predecessors nor successors, records that happened without prior knowledge about existence of current record(s).
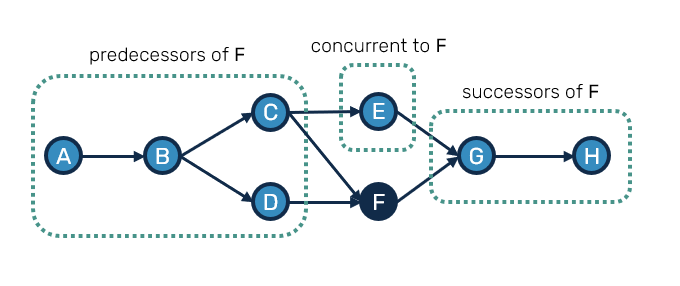
These are pretty common concepts, that are crucial in order to understand and operate the partially-ordered log.
func (log *POLog) Predecessors(heads []ID) []*Record {
var res []*Record
log.predecessorsF(heads, func(i int, p *Record) {
res = append(res, p)
})
return res
}
// Returns records that are successors or concurrent to given heads
func (log *POLog) Missing(heads []ID) []*Record {
v := log.predecessorsF(heads, func(i int, r *Record) {
/* do nothing */
})
var res []*Record
for i, p := range log.records {
if !v.Get(i) {
res = append(res, p)
}
}
return res
}
// Traverses over the head records and their predecessors, executing given
// function f with patch index position in a log and record itself.
// Returns a Bitmap which includes indexes describing all visited records
func (log *POLog) predecessorsF(heads []ID, f func(int, *Record)) Bitmap {
q := log.indexes(heads) // queue of records to visit
visited := NewBitmap(len(log.records))
for {
i, ok := pop(&q) // get next record to visit in FIFO order
if !ok {
break // q is empty
}
// check if we haven't visited this patch already
if !visited.Get(i) {
visited.Set(i, true)
p := log.records[i]
// append parents in to-visit queue
q = append(q, log.indexes(p.parents)...)
f(i, p)
}
}
return visited
}
Persistent stores
Since the partially ordered log usually is not truncated, it could possibly outgrow the available memory. Moreover once the state is established, most of the records are rarely used. It's natural to build a log backed by some persistent store. It could be a key-value based one (like LMDB or Sanakirja used by Pijul), but it could also be a higher level database.
Below you can see a simple SQL schema and queries that can be used to store and navigate over the directed graph of records represented as a nodes and edges tables.
-- records
CREATE TABLE IF NOT EXISTS nodes(
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
hash NCHAR(32) NOT NULL UNIQUE,
author NCHAR(32) NOT NULL,
sign NCHAR(64) NOT NULL,
content BLOB NOT NULL
);
-- relationships between records
CREATE TABLE IF NOT EXISTS edges(
parent_id INTEGER NOT NULL,
child_id INTEGER NOT NULL,
PRIMARY KEY(parent_id, child_id),
FOREIGN KEY (parent_id) REFERENCES nodes(id),
FOREIGN KEY (child_id) REFERENCES nodes(id)
);
-- get all predecessors of record 'xyz'
WITH RECURSIVE predecessors(id) AS (
SELECT id as parent_id FROM nodes WHERE hash IN ('xyz')
UNION
SELECT parent_id
FROM edges s
JOIN predecessors p ON s.child_id = p.id
)
SELECT * FROM predecessors;
-- get all edges or nodes created after or concurrently to record 'xyz'
WITH RECURSIVE predecessors(id) AS (
SELECT id as parent_id FROM nodes WHERE hash IN ('xyz')
UNION
SELECT parent_id
FROM edges s
JOIN predecessors p ON s.child_id = p.id
)
SELECT child_id FROM edges s WHERE child_id NOT IN predecessors;
Given the proximity between the concepts of distributed version control systems and topic we're describing here, you may find interesting that Fossil - a version control system developed and used by SQLite creators - is in fact backed by SQLite itself.
Replication
Basic replication protocol operates on two concepts: upon connection with remote peer try to pull missing records and once this is done then be ready to push and receive all new records onwards.
For operation-based approach we used in the past we were able to represent state of the world using vector clocks. Each peer at the beginning was sending its own vector clock to its remote counterpart, which then was able to compute what new records happened since given vector clock.
Since we don't rely on vector clocks here, we'll make each peer send a list of its latest record IDs instead. Unsurprisingly we'll call them heads (another analogy to Git). Unless there were several updates made concurrently by the different peers, heads list will usually consist of the single element.
But how do we figure out which records should be send back to requester? Fortunately, a log.Missing method we've shown before is capable of returning records which happened after or concurrently to provided heads. However, what if the requester had sent heads of records we've never seen so far? There is more than one way to figure this out, but we're going with the most brute force solution:
type Peer struct {
pub ed25519.PublicKey // Peer's public key, equals to Author
priv ed25519.PrivateKey // Peer's private key, used for signing
heads []ID // all newly created records on this peer will refer to heads as their parents.
store *POLog // record log
stash *Stash // Stash used as a temporary container for records which are being resolved
missingDeps map[ID]struct{} // "known" missing parents preventing records from stash to be integrated into store
}
func negotiate(src *Peer, dst *Peer) error {
heads := src.Announce() // A sends its own most recent PIDs
missing := dst.NotFound(heads) // B picks IDs of the records it has not seen yet
for len(missing) > 0 { // until all missing records are found
records := src.Request(missing) // send request to A asking for missing PIDs
err := dst.Integrate(records) // B tries to integrate A's records
if err != nil {
return err
}
missing = dst.MissingDeps() // B recalculates missing records
}
return nil
}
func (p *Peer) Integrate(rs []*Record) error {
changed := false
for _, r := range rs {
if err := r.Verify(); err != nil {
return err // remote patch was forged
}
if p.store.Contains(r.id) || p.stash.Contains(r.id) {
continue // already seen in either log or stash
}
// check if there are missing predecessor records
var missingDeps []ID
for _, dep := range r.parents {
if !p.store.Contains(dep) {
if !p.stash.Contains(dep) {
missingDeps = append(missingDeps, dep)
}
}
}
if len(missingDeps) > 0 {
// if there were missing predecessors, stash current record
p.stash.Add(r)
for _, dep := range missingDeps {
p.missingDeps[dep] = struct{}{}
}
} else {
// all dependencies were resolved, add record to log
if err := p.store.Append(r); err != nil {
return err
}
delete(p.missingDeps, r.id)
changed = true
}
}
if changed {
// if any record was successfully integrated it means, we may
// have stashed records that have their dependencies resolved
// and are ready to be integrated as well
p.heads = p.store.Heads()
rs = p.stash.UnStash()
if len(rs) != 0 {
return p.Integrate(rs)
}
}
return nil
}
Basically we traverse the graph of records from the latest to the oldest. Each traversal step requests for a batch of concurrently committed records and checks it their parents dependencies are satisfied. If some parents were missing from current log, we stash current records aside and then fetch the parents. Do this recursively until all dependencies have been fetched. Once this is done, reapply stashed records in LIFO order.
Performance considerations
While the ideas we presented may sound tempting, there are some serious performance issues that don't let us scale this approach over certain point:
- Metadata overhead which is pretty popular problem in all CRDT-related algorithms. For practical reasons the minimum is 2 * 32B = 64B per committed record (ID of the current record + ID of its parent dependency). While it doesn't sound bad, it can be quite a lot for some scenarios eg. text editing, where each key-stroke is separate operation: at the moment there are no proved ways to make this algorithm work with update splitting/squashing.
- Our algorithm itself is very naïve and comes with one serious downside - each loop iteration is basically a network RPC. If there's a long missing record dependency chain between two peers it means multiple roundtrips trying to fetch all missing parents. Thankfully due to wild popularity of Git there are many articles, papers and implementations of record negotiation/reconciliation between peers. While some of them are pretty Git specific, others are capable targeting even closer to our use cases. We might try to cover them in the future.
Unfortunately, there are still unanswered questions in this problem domain, which at the moment may make this approach hard to scale for real-time collaboration. It's also the reason, why we can observe its wider adoption when we talk about manually committed changes (present ie. in distributed version control) instead.
References
- Github repository branch with full code, the snippets in this blog post come from.
- HyperHyperSpace which is a JavaScript library build around security and CRDTs in mind. It shares a lot with the ideas we had presented here.
- Pijul which is a CRDT-based distributed version control system we already mentioned at the beginning.
- Byzantine Eventual Consistency paper discussing possible improvements to replication protocol used by content-addressed partially-ordered log we presented here.
Comments