Some time ago, we covered an idea behind HyParView, a cluster membership protocol that allowed for very fast and scalable cluster construction. It did so by using the concept of partial view: while our cluster could be build out of thousands of nodes, each one of them would only be actively talking to a small subset of the entire cluster.
However cluster in which nodes are not fully interconnected - while easier to scale - comes with some trade offs. A popular use case - and the one, which we're going to solve today - is situation when a single node wants to broadcast a message to all other nodes in the cluster. How can we do so efficiently, reliably and with respect to overall network usage? These issues have been addressed by Plumtree - a gossip protocol that nicely complements HyParView we discussed in the past.
Problem description
The question we need to answer is: given that a node can communicate only with a subset of other nodes in the cluster, how can we make sure that its messages will eventually be received by all nodes? There are two popular approaches to this problem: mesh flooding and spanning trees.
Mesh flooding is very simple concept, we just broadcast the same message to all of our active connections, then they will forward it to all of their connections (except origin/sender), and so on. To prevent message from flying around infinitely, we attach a time to live counter (TTL) to it. It should be high enough for our message to reach far end of the cluster topology. Alternatively we could attach a list of already visited nodes with the message, but this doesn't scale well as message size starts to grow together with a cluster size. To avoid sending the same messages over and over we also maintain cache of the most recently seen messages.
Mesh flooding comes with another downside - even with if cache allows us to discard duplicates, they still are "flooding" the network. For this reason this approach may scale badly to size of a cluster and frequency in which we need to use our broadcast.
Another approach is first building a spanning tree of nodes in a cluster. This way we have a nice acyclic tree which gives us an efficient gossip routes that span over all of the nodes and makes sure that the same message won't be send or received twice by the same client (if it's not necessary). But problem here lies in resiliency. As nodes may get disconnected, the structure of a graph changes and branches of our broadcast tree may get occasionally severed from root node (an original message sender), causing messages not to be send to all nodes.
If we could only find a way to for a spanning trees to heal and reconnect themselves upon connection failures...
Epidemic broadcast trees
Here, we'll cover some ideas and implementations behind Plumtree, which is a broadcast protocol defined to work over partially connected cluster of machines. You can read about it more in the original paper, which is quite easy to follow. While the Plumtree doesn't have to work over HyParView protocol, such approach is very convenient and the implementation we're going to use here works as extension of HyParView. For this reason, make sure that you are familiar with basics of HyParView before continuing.
Plumtree relies on notion of two peer types:
- Eager peers are notified right away every time current node received a gossip request.
- Lazy peers are notified about identifiers (digests) of the messages in some time intervals. We can use these periodic notifications to detect severed branches of our broadcast tree.
Do not conflate notion of eager/lazy peers from Plumtree protocol with active/passive view of HyParView protocol. Both eager and lazy peers belong to active membership view (which represents active connections between peers). However unlike active membership graph, which can contain cycles, Plumtree eager peers are connected in an acyclic tree structure.
Tree construction
Our first step is to take a graph of partially connected membership cluster and build a spanning tree out of it. How? Since we're building on top of existing membership protocol, let's start from defining how are we're going to react on new peers events in our cluster - this is how our broadcast tree is going to grow or shrink:
let onNeighborUp (state: State) peer = async {
return { state with EagerPushPeers = Set.add peer state.EagerPushPeers }
}
let onNeighborDown (state: State) peer = async {
return { state with
// Remove notifications about messages missing from given peer
Missing = state.Missing |> Set.filter (fun m -> m.Sender = peer)
// Eager & lazy peers need an active connection. Once it's
// down we need to remove that peer from both sets
EagerPushPeers = Set.remove peer state.EagerPushPeers
LazyPushPeers = Set.remove peer state.LazyPushPeers }
}
This was trivial: we're simply start by assuming a direct passive link between connected nodes. Later on this link may be invalidated. We don't need to do anything more until there's a message to be broadcasted:
let onBroadcast (state: State) (data: Binary) = async {
let msgId = Guid.NewGuid()
let gossip = { Id = msgId; Round = 0UL; Data = data }
let state = { state with ReceivedMessages = Map.add msgId gossip state.ReceivedMessages }
let! state = lazyPush state gossip state.Self
do! eagerPush state gossip state.Self
return state
}
Each time we're about to send some payload, we're going to setup a unique ID for it together with a TTL (Time To Live) counter - TTL must be long enough for a gossip to reach the other end of the cluster. Then we're going to do several things - we'll start from caching that gossip envelope. Since we don't invalidate eager peer links right away, we must be prepared that our broadcast tree has in fact cycles: initially it's not really a tree.
We're going to gossip our message to all eager peers - they are considered to be the main branches of our broadcast tree.
let eagerPush (state: State) gossip sender = async {
let except = Set.ofArray [| state.Self; sender |]
do! (state.EagerPushPeers - except)
|> Seq.map (fun peer ->
state.Send(peer, Gossip gossip))
|> Async.Parallel
|> Async.Ignore
}
Keep in mind that this message may arrive more than once to the same peer - hence existence of ReceivedMessages buffer. If that happens, we respond to duplicate by sending a Prune reply to sender. This way we inform that the message was already received via some other route. This implies existence of cycles in our graph, so we expect a sender to downgrade this connection from eager into lazy one.
let private onPrune (state: State) sender = async {
// move sender from eager to lazy peer status
return addLazy sender state
}
We could visualize the entire tree construction with following animation:
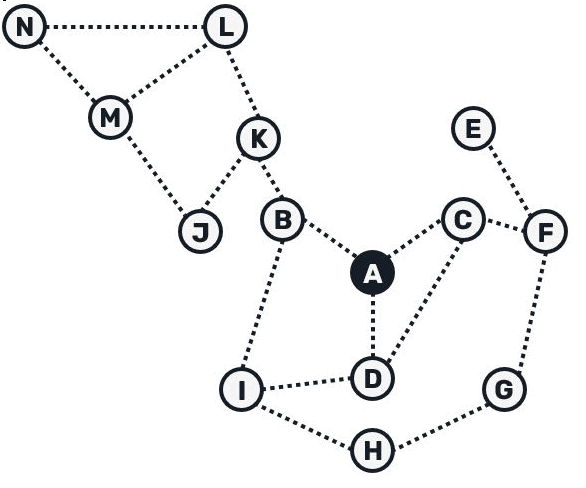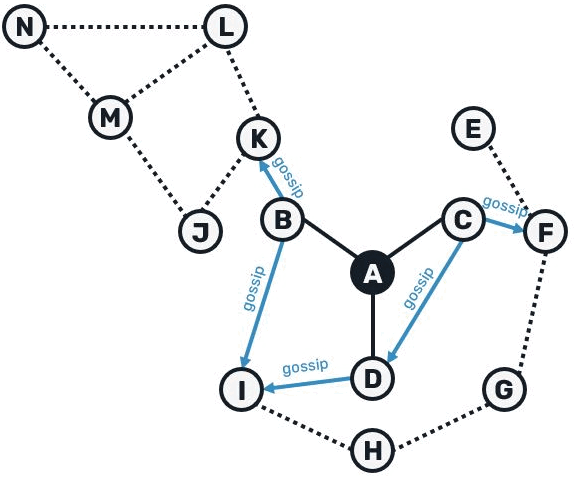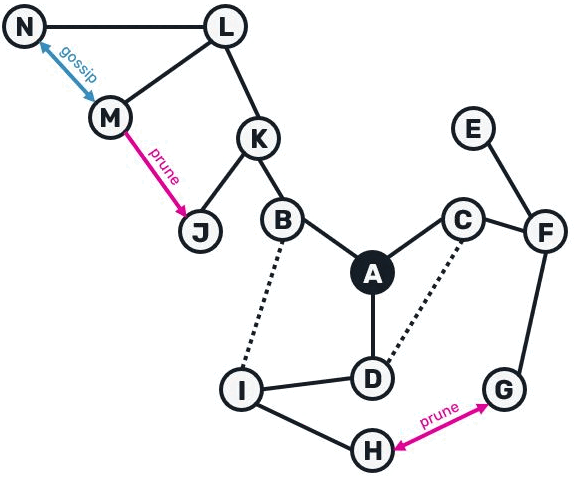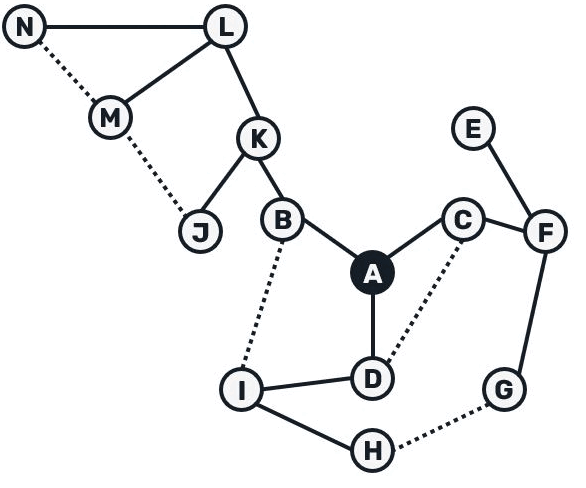
While broadcast trees allow us to avoid flooding the network with duplicates, their maintenance gets pretty difficult once network connections get unstable: as we're relying on a message getting delivered through a single source, once this connection fails, we need to find another route and figure out which messages went missing. Now let's discuss the second part of the Plumtree protocol - the tree repair.
Tree repair
Since our broadcast depends on the underlying graph of interconnected peers, we had split them into eager an lazy ones. Just like we keep a list of eager peers (representing active communication path of a broadcast tree), we also maintain a list of lazy peers. These are "backup" nodes that we know are alive but don't communicate with regularly, since they confirmed that they are part of the tree by connecting to some other node. However, if their connection gets broken eg. because eager peer went down, we need to detect that. To make it possible we'll introduce operation called lazy push.
The idea is that we occasionally will ping our lazy nodes - this however won't happen directly after receiving gossip. Instead in our lazy push implementation we'll simply stash our gossip.
let lazyPush (state: State) (gossip: Gossip) sender = async {
let lazyQueue =
Set.remove sender state.LazyPushPeers
|> Set.fold (fun acc peer ->
(gossip.Id, gossip.Round, peer)::acc) state.LazyQueue
return { state with LazyQueue = lazyQueue }
}
Our lazy queue will be scanned by dedicated process, which we'll schedule repeatedly within some time interval:
let onDispatch (state: State) = async {
let gossips =
state.LazyQueue
|> List.fold (fun acc struct(id, round, peer) ->
let msg = struct(id, round)
match Map.tryFind peer acc with
| None -> Map.add peer [msg] acc
| Some existing -> Map.add peer (msg::existing) acc) Map.empty
do! gossips
|> Seq.map (fun (KeyValue(peer, grafts)) ->
state.Send(peer, IHave(List.toArray grafts)))
|> Async.Parallel
|> Async.Ignore
return { state with LazyQueue = [] }
}
What's important to notice, is that we don't send message payload itself. Instead we just forward a digest, which can be unique identifier, consistent hash of a message or (possibly) a bloom filter of entire batch of the most recent gossips. Here we're assigning identifier to each message. It's sole purpose is to give other side enough info to determine if message(s) was missing.
For the receiver, we'll use message ID together with peer's local cache of ReceivedMessages to determine possible diff that will tell us which messages haven't been received yet:
let iHave (state: State) (messageId: MessageId) (round: Round) sender =
if Map.containsKey messageId state.ReceivedMessages then
let timers = Set.add messageId state.Timers
let missing = { MessageId = messageId; Sender = sender; Round = round }
{ state with Timers = timers; Missing = Set.add missing state.Missing }
else state
let onIHave state notes sender = async {
let nstate =
notes
|> Array.fold (fun state (msgId, r) -> iHave state msgId r sender) state
for messageId in nstate.Timers - state.Timers do
// this message should be scheduled to trigger subroutine
// after configured delay
do! state.Output.Send(state.Self, { Message = Timer messageId; Peer = state.Self })
return nstate
What's very important is that upon receiving IHave message we don't send reply right away, even if we confirmed that other side has messages that we haven't seen. It's because these messages may still be in-flight from our eager peers route, but they didn't reached us before corresponding IHave message eg. because of some network lag. To take that into account, we're introducing a delay. Once that period passes, we can start preparing the response.
let private removeFirstAnnouncement (missing: Set<Announcement>) msgId =
// get the first peer who announced the message that we're missing
let found = Seq.find (fun m -> m.MessageId = msgId) missing
(Set.remove found missing), found
let private onTimer (state: State) (msgId: MessageId) = async {
let! timers = async {
if Set.contains msgId state.Timers then return state.Timers
else
//TODO: schedule timer to send this message after graft timeout
let msg = { Message = Timer msgId; Peer = state.Self }
do! state.Output.Send(state.Self, msg)
return Set.add msgId state.Timers }
let missing, announcement = removeFirstAnnouncement state.Missing msgId
let state = { state with Missing = missing }
let state = { addEager announcement.Sender state with Timers = timers }
do! state.Send(announcement.Sender, Graft(msgId, announcement.Round))
return state
}
Since the same message digest (ID) may have arrived from multiple peers as part of lazy push, we respond on them one at the time. If we'd answer to everyone at the same time we'd risk creating multiple routes for the same broadcast tree, therefore introducing duplication and (potentially) cycles.
In our case, Graft response works as negative acknowledgement - it informs recipient that message with given digest was not received within expected timeout from the moment IHave info about that message has been sent. This implies necessity of healing the tree by promoting the lazy connection into eager one and redelivering the missed message.
let private onGraft (state: State) messageId sender = async {
let state = addEager sender state
match Map.tryFind messageId state.ReceivedMessages with
| None -> return state
| Some gossip ->
do! state.Send(sender, Gossip gossip) // redeliver gossip
return state
}
The entire process of tree recovery could be summarized as:
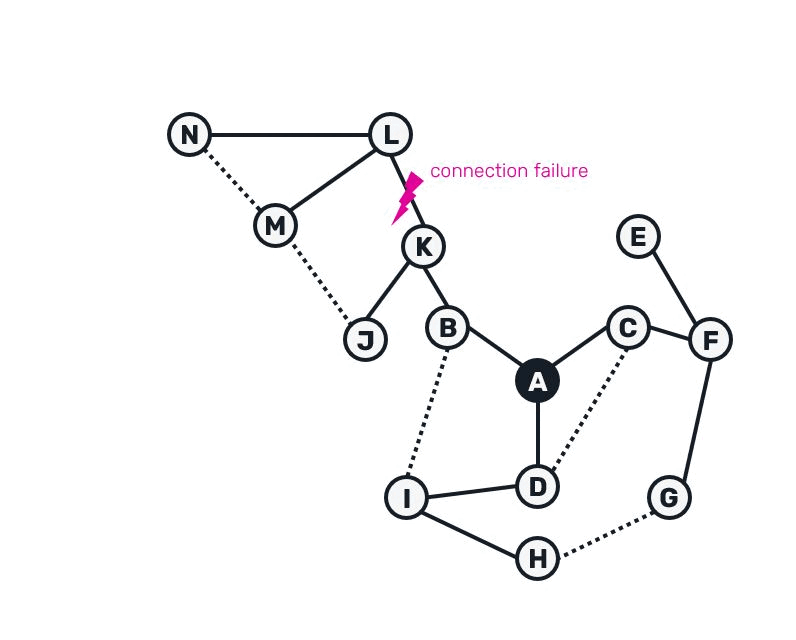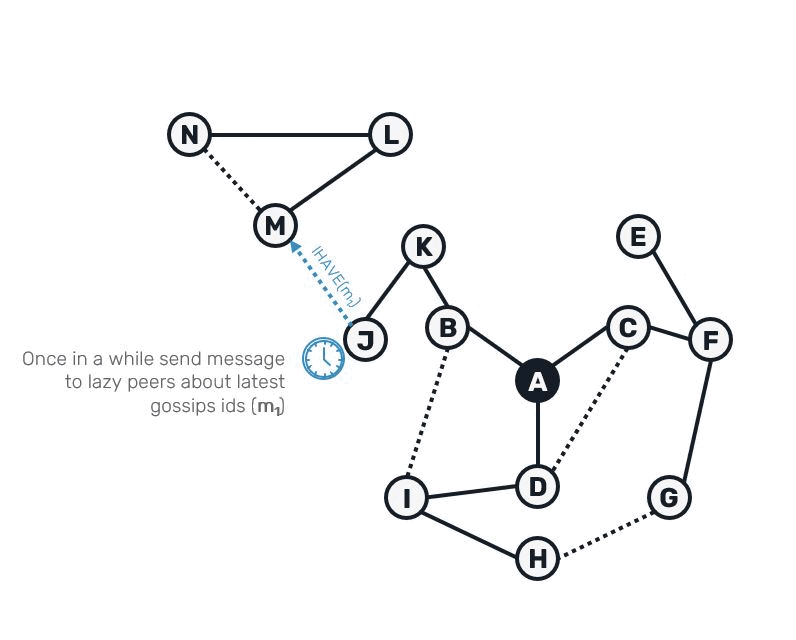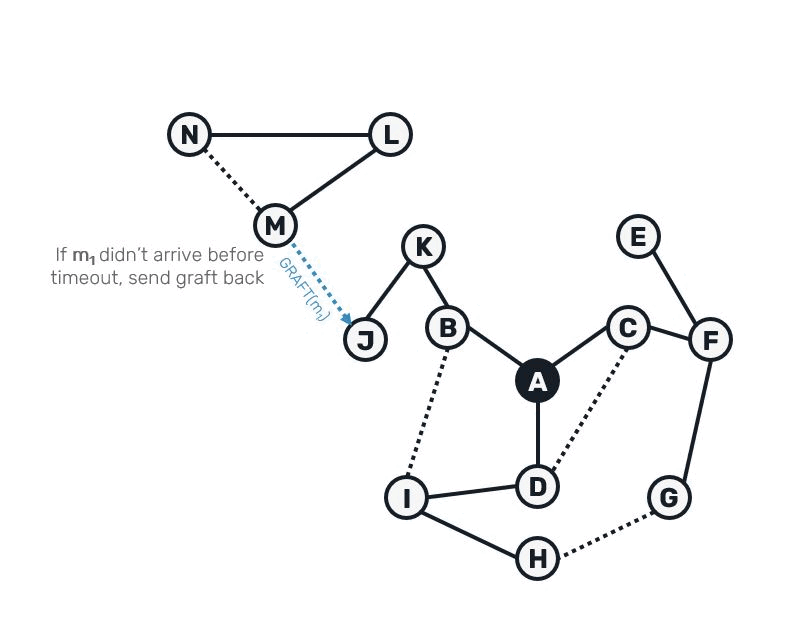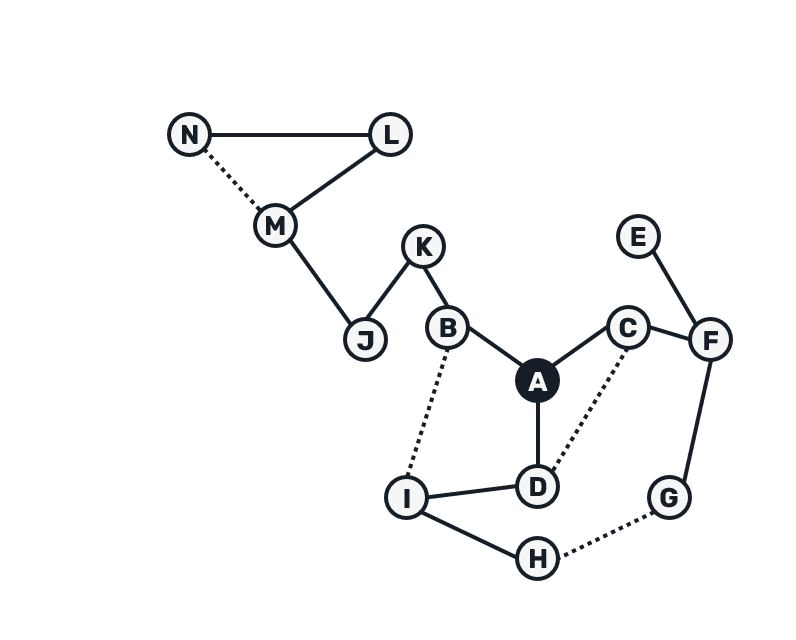
Notice that we need to buffer the gossip for a possible redelivery for at least as long as it takes to trigger IHave message to be sent and for Graft to be potentially received back.
Summary
In this blog post we went through technical details of Plumtree epidemic broadcast trees protocol implementation. We went through its two core concepts: tree construction and healing. In the snippet code we didn't cover some of the cases eg. invalidating and pruning received messages buffer. If you're interested in more industrial grade code samples, I can recommend you looking into the Partisan repository (written in Erlang).
The HyParView/Plumtree combination was created to support gossiping data across clusters consisting of thousands - or even tens of thousands - of peers in effective manner with a respect to underlying hardware usage. This comes at the price: broadcast trees usually introduce higher time to propagate when compared to meshes (especially when we take into account severed branches and the necessity of healing them). Keep that in mind when considering using this approach for low latency scenarios.
Comments