In this post I'll explain, how the events sourcing concepts has been used by Akka.NET persistence plugin to create statefull actors being persisted and work in reliable way. My major goal is to give you an introduction over basic Akka.Persistence primitives and to describe how state recovering works for persistent actors.
State persistence and recovery
The most notable novelty, the Akka.Persistence offers, is a new actor type, you could possibly inherit from - a PersistentActor. The major difference when compared to standard Akka's actors is that it's state can be persisted into durable data store, and later recovered safely in case of actor restart. There is a variety of persistent backends already supported, including:
After persisting a state, it may be recovered at any time, once an actor gets recreated.
Persisting actor's state
There are two ways of storing a state. Major (required) is event sourcing - saving the list of all state changes as soon, as they occur. The second one is state snapshotting - serializing the whole state of an actor into a single object and store it. What is very important, snapshotting is only an optimization technique, not a reliable way of achieving persistence within in-memory systems. Reason for that is, that while you may ensure to store an actor state in case on it's failure, you're not able to ensure state persistence is case of external problems (infrastructure crashes, outages etc.).
Basic persist mechanism consists of several steps:
- After receiving a command, actor tries to persist an event, with a callback to be called, once persistence has been confirmed. In order to do so actor should invoke
Persist(event, callback)method. There is also another version calledPersistAsync, which may take advantage of event batching - useful, when a frequent state updates are expected. - Event is send to dedicated actor - event journal - which stores it in the persistent backend.
- If message has been persisted successfully, journal sends a confirmation message back to actor. It updates it's state using previously defined callback. All state updates, that should be persisted, must be defined only inside persist callback. If you'll try to alter persistent state outside of the callback, you're risking potential state corruption.
- In case, when journal encountered a problem - usually due to problems or lack of response from backend provider - a failure message will be send. In that case, actor will restart itself. You may consider to use Backoff Supervision pattern in order to apply exponential backoff mechanism to reduce recovering footprint in case of cascading failures.
In case of snapshotting, there is no need for callbacks - whole mechanism is fully asynchronous. Use SaveSnapshot method for this purpose.
You can see whole process in the animation below:
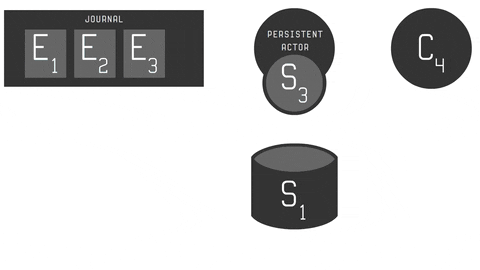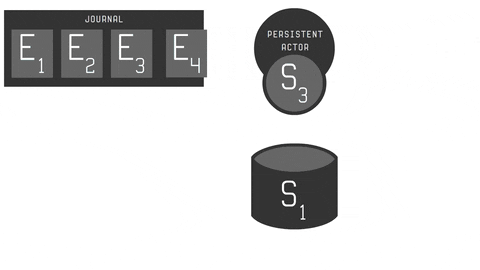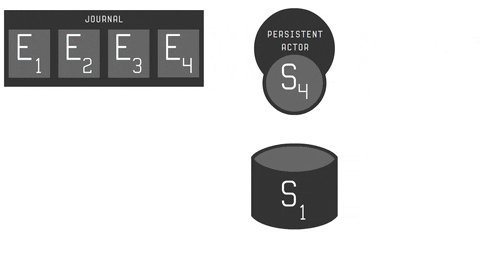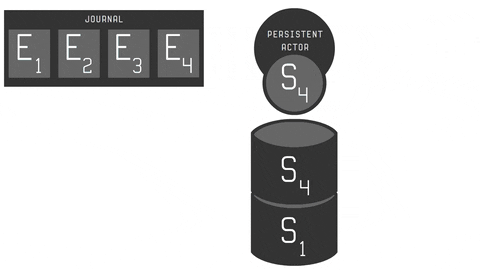
- C - message (command) to be handled by persistent actor, which may result in producing a zero or more events.
- E - sequenced events used to trigger actor state change.
- S - persistent actor state, that may be snapshotted. Remember: snapshotting is optional here.
State recovering
Actor state recovery logic is encapsulated in the separate method (called OnRecovery or ReceiveRecovery). What is important here, this method should always produce a deterministic behavior - during recovery actor should neither try to persist any events nor communicate with other actors.
Here's how it works:
- Actor asks journal for the latest known snapshot of it's state. State is returned inside
SnapshotOffermessage. If no snapshot has been found, offer will contain null. Warning: don't rely on snapshot versioning, as recovered snapshot may have earlier version, than the one you've send before recovering - remember, what I said about asynchronous nature of this operation? - Second step is to replay all events since the received snapshot creation date. If no snapshot was received, the whole event stream will be replayed. Event messages are received in the same order, as they were produced.
- Once actor fully recovered, it's invoking
OnReplaySuccessmethod. If any exception has occurred,OnReplayFailurewill be invoked instead. Override them, if you need a custom action once persistent actor is ready.
What I think is worth notice, is that persist/recovery mechanism is not aware of current actor behavior. Therefore, if you're having state machines (i.e. by using Become) in your actor, you're in charge of returning to the correct step after recovery.
One of the tradeoffs of persistent actors is that, they lay heavily on CP (Consistency) site of CAP theorem ;) . What does it actually mean?
In terms of command side evaluation, each persistent actor is guaranteed to maintain consistent memory model - use Defer method when you need to execute some logic, after actor has updated it's state from all stored events. Events are stored in linear fashion - each one of them is uniquely identified by PersistenceId/SequenceNr pair. PersistenceId is used to define stream inside event log related to a particular persistent actor, while SequenceNr is a monotonically increasing number used for ordering inside an event stream.
The negative side of that approach is that persistent actor's event stream cannot be globaly replicated, as this may result in inconsistent stream on updates. For the same reason your persistent actors should be singletons - there should never be more than one instance of an actor using the same PersistentId at the time.
Persistent Views
Sometimes you may decide, that in-memory model stored by persistent actor is not exactly what you want, and you want to display data associated with it in different schema. In this case Akka.Persistence gives you an ability to create so called Persistent Views. Major difference is that while persistent actor may write events directly to an event journal, views work in read only mode.
You may associate a persistent view with particular actor by joining them using PersistenceId property. Additionally since one persistent actor may have many views associated with it (each showing the same stream of events related to particular entity from a different perspective), each view has it's own unique persistent identifier called ViewId. It's used for view snapshotting - because views can have possibly different states (from the same stream of events), their snapshots must be unique for each particular view. Also because views don't alter an event stream, you can have multiple instances of each view actor.
How persistent views update their state, when new event is emitted? Akka.Persistence provides two methods by default:
- You may explicitly send
Updatemessages through a view's ref to provoke it to read events from the journal since last update. - All views used scheduled interval signals (
ScheduledUpdatemessages) to automatically update their internal state when signal is received. You may configure these by settingakka.persistence.view.auto-update(on by default) andakka.persistence.view.auto-update-interval(5sec by default) keys in your actor system HOCON configuration.
You probably already noticed, that views are eventually consistent with the state produced by their persistent actor. That means, they won't reflect the changes right away, as the update delay may occur.
NOTE: This part of Akka.Persistence plugin is the most likely to change in the future, once reactive streams will be fully implemented in Akka.NET.
AtLeastOnceDelivery
The last part of the Akka.Persistence is AtLeastOnceDeliveryActor. What's so special about it? By default Akka's messaging uses at-most-once delivery semantics. That means, each message is send with best effort... but it also means that it's possible for a message to never reach it's recipient.
In short at least once delivery means that message sending will be retried until confirmed or provided retry limit has been reached. In order to send a message using at-least-once-delivery semantics, you must post it with Deliver method instead of Tell. This way messages will be resend if not confirmed in specified timeout. You can adjust timeout by specifying akka.persistence.at-least-once-delivery.redeliver-interval in your HOCON configuration - by default it's 5 seconds. It's up to message sender to decide, whether to confirm message or not. If so, it may confirm a message delivery using ConfirmDelivery method.
What if our actor is trying to deliver a message, but no acknowledgement is being received? In that case we have 2 thresholds:
- At some point your actor will see, that messages has not been confirmed for a particular number of times. If that will occur it will receive a
UnconfirmedWarningmessage with list of unconfirmed messages. At that point you may decide how to handle that behavior. You may specify how many retries are allowed before warning to be received by setting anakka.persistence.at-leas-once-delivery.warn-after-number-of-unconfirmed-attemptskey in the HOCON config (it's 5 by default). - Since each unconfirmed message is being stored inside current actor, in order to prevent burning down all of the program's memory, after reaching specified unconfirmed messages limit it will actively refuse to
Deliverany more messages by throwingMaxUnconfirmedMessagesExceededException. You can set the possible threshold usingakka.persistence.at-least-once-delivery.max-unconfirmed-messageskey (it's 100 000 by default). This limit is set per each actor using at-least-once-delivery semantics.
All unconfirmed messages are stored on the internal list. If you want, you may snapshot them using GetDeliverySnapshot and set back on actor recovery using SetDeliverySnapshot methods. Remember that this methods are meant to be used for snapshotting only and won't guarantee true persistence without event sourcing for the reasons described above in this post.
Be cautious when making decisions when to use this semantics in your code. First it's not good for performance reasons. Second it would require from you recipient to have idempotent behavior, since the same message may be possibly received more than once.
Journals and Snapshot Stores
Last part of the Akka.Persistence are journals and snapshot stores, that make all persistence possible. Both of them are essentially actors working as proxy around underlying persistence mechanism. You can decide what direct implementation of the underlying backend to choose. You can also choose to create your own. If you decide to do so see my previous post to get some more details.
In order to set a default persistence backend, you must set akka.persistence.journal.plugin or akka.persistence.snapshot-store.plugin to point at specific HOCON configuration paths. Each specific plugin should describe it's configuration path, however it may also require some custom configuration to be applied first.
It's possible for different actor types to use different persistence providers. It's possible with persistent actor's JournalPluginId and SnapshotPluginId properties, which should return HOCON configuration paths to a particular journal/snapshot.
Comments