Have you ever run into N+1 select problems with your GraphQL endpoint? If so, don't worry anymore. Today we're going to generalize and solve this kind of issues as well as discuss and explain the mechanics behind them. Also as usual, we don't cover only theory but also a F# implementation, which - if you're impatient - can be found here.
What's the problem
N+1 Select is a common name for a problem most often seen in Object Relational Mapping libraries. It's usually result of not prefetching all required data from database ahead of operating on it, in result causing our ORM to lazily fetch every missing piece when its demanded. Since this kind of issue is often combined with processing (a missing) data within loops, we easily run into situation when instead of doing a single database query, we're doing it for every loop iteration, seriously crippling performance of our system.
This problem became even more apparent - and harder to solve - with introduction of GraphQL, which enabled API consumers to send arbitrary requests. This dynamic nature of GraphQL queries makes it harder to predict, what data needs to be prefetched in order to serve the query. We cannot hardcode it, as requirements may be changing from one query to another. Moreover, different segments of the query (called resolvers) are often isolated and don't exactly know which other parts of the query are about to be fetched - some libraries solve this by creating query execution plans - or how to synchronize data access to avoid fragmented retrieval of information.
N+1 Select issue can also be described in more general terms - we are dealing with multi-step tree of async computations, some of which have dependencies on other computations being performed first, while others can be run in parallel, isolated from each other. Example: when having Users and Orders table, if you want to serve data about users and their orders, orders depend on users, but one order request is isolated/independent from another, same for individual users.
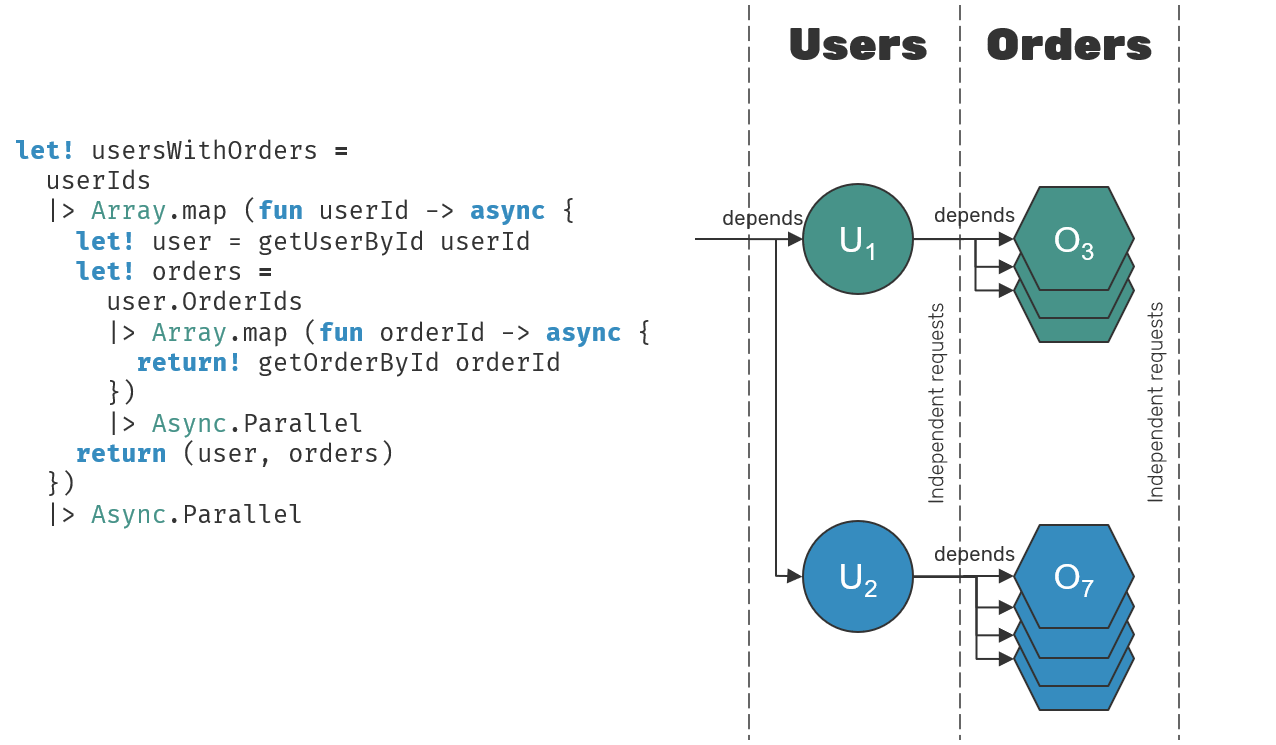
Optimizations around this sort of dependent/isolated and sequential/parallel relationships where researched, and I think that for the purpose of this post we can divide them into two categories:
- Original approach promoted by Facebook's Haxl library, which was adopted by others like ZQuery or FSharp.Data.DataLoader. These are focusing on defining dedicated monads/applicatives capable of representing dependent/independent computations and deferring their execution in introspective, "free" manner.
- Another way was introduced by dataloader.js and spread over by many other platforms, including C# and Rust. It focuses on intelligent managing and sidelining the task execution queue filled by async/await mechanisms of these languages.
These approaches even when using different techniques, still are based in similar foundations. They try to optimize parallel operations by introducing batching and substituting individual requests with an equivalent operation that works over batches. Imagine replacing N queries for a given ID with one passing a list of N given IDs. They usually also support caching of once retrieved values - which helps deduplication of requests and is especially useful when it comes to building data graphs containing cycles.
Here we're going to cover 2nd approach. The reason is simple - 1st approach relies on building custom effect system that needs to be propagated by the rest of the application, making it quite intrusive. It's highly unlikely that you'll find another system, framework or library integrated to use and propagate your custom effects onward... especially since we didn't define them yet. This could be solved with Higher Kinded Types, but we don't have them in F#.
Making up promises
First, we need some building blocks to begin with. One of the components, we're going to need, is a value container that can be asynchronously awaited for until the value is provided. If you're using .NET TPL, then you know that we have TaskCompletionSource<T> which serves this purpose. Same for Promises in JavaScript.
In F# Async however we don't have such thing provided as part of standard library. It's quite important, as Async is not really an object representing a computation in progress (like .NET Tasks in most cases), but a description of a computation that needs to be started to do its job - actual object representing computation in progress is called AsyncActivation and usually is not visible to us. It also means, that binding to async computation multiple times will cause its code to be run multiple times.
async {
let sleep1s = Async.Sleep 1000
do! sleep1s
do! sleep1s
} // total time passed: 2 seconds
task {
let sleep1s = Task.Delay 1000
do! sleep1s
do! sleep1s
} // total time passed: 1 second
This is a result of lazy nature of F# Async and one of the properties of functional programming. That's what we want to avoid here, otherwise our fetching function would be called for each element in processed batch instead of once, defating its purpose. Fortunately, this is pretty well known problem. Some variants of ML languages (which also F# inherits from) like Concurrent ML define structures known as ivar or mvar, which semantics we're going to use bellow:
IVar<'t>is write-once cell, which reflects behavior ofTaskCompletionSource<'t>. It can be written to only once and asynchronously awaited for a value to appear. In case when the value was already there, all future awaiters are being completed immediately. This is the data structure we're going to use.MVar<'t>is another variant, that allows swapping the value inside multiple times. We're not going to use it here - it can have a funky behavior in terms of data races - but it's worth to know about the existence of it. It has no equivalent in .NET standard library.
We'll start from defining an internal state object of our IVar container.
type VarState<'t> =
| Empty of ('t->unit) list
| Full of 't
It can work in two modes:
Emptymeans, that value was not yet provided. In that case we're collecting all completion callbacks, that come from pending awaiters.Fullinforms, that the cell is filled. In that case awaiter list is no longer necessary, as we can resolve them as they come.
With this in mind, our IVar type looks like this:
type IVar<'t> () =
let mutable state: VarState<'t> = Empty []
let accept (success, _failure, _cancel) = ...
let async = Async.FromContinuations accept
member this.Value: Async<'t> = async
member this.TryWrite (value: 't): bool = ...
member this.Write (value: 't): unit =
if not (this.TryWrite value) then
raise (NonEmptyVarException "Cannot write value to non-empty IVar.")
We skipped some of the implementations to discuss them in a second. First thing, we're going to look at is the accept function. It's used to create a generic completable Async object using Async.FromContinuations. What you can see here is that it's a function that takes a triple of callbacks, used to denote one of the tree possible final outputs of our async - a successfully computed value, a failure with exception or a cancellation.
For updating the state when an async activation binding hits our IVar.Value, we need to be sure that this operation is thread safe, and we're going to use lockless updates to make it so.
let accept (success, _failure, _cancel) =
let rec update success =
let old = Volatile.Read &state
match old with
| Full value -> success value
| Empty list ->
let nval = Empty (success::list)
if not (obj.ReferenceEquals(old, Interlocked.CompareExchange(&state, nval, old))) then
update success // retry
update success
We described this algorithm in the greater detail in the past. Here we only glimpse over it. What we're basically trying to do is to accept incoming callbacks - if our IVar already has value in it, we're calling the callback immediately. Otherwise we add it to awaiters list and try to update the state using atomic hardware instructions. If another thread tried to do the same in the meantime, Interlocked.CompareExchange can return state updated by another thread. If that happens we'll simply retry the operations - since our state is based on immutable data structures, it's safe to do so.
Another operation using atomic compare and swap semantics is writing a value into a cell. Here we're trying replace our Empty state with Full value. If that succeeds, we're iterating over all awaiters callbacks, providing them with value.
type IVar<'t>(?value: 't) =
member this.TryWrite (value: 't): bool =
let rec update value =
let old = Volatile.Read &state
match old with
| Value _ -> false
| Full awaiters ->
if obj.ReferenceEquals(Interlocked.CompareExchange(&state, Full value, old), old) then
for resolve in awaiters do
resolve value
true
else update value // retry
update value
While iteration itself happens in LIFO order, it doesn't really matter here.
Async batching
With our "promises" ready, we can now go to building actual solution. The core of the idea depends on cooperation of two different types:
- A batching/caching object, which we supplement with our function for resolving sequences of requests. It exposes a method to perform requests one by one and hides the complexity to putting them in batches.
- A custom synchronization context - this class is related to the .NET threading model. When our async code is being started (eg. during operations like
Async.Start), we can instruct async activation, how should it be run on CPU via synchronization context. By default it uses a global .NET thread pool, but we'll need to alter this behavior a little.
The core of our API in action will look like this:
let ctx = DataLoaderContext() // custom synchronization context
let loader = DataLoader(ctx, fun ids -> async {
use! db = openDb connectionString
let! users = db.QueryAsync<User>("select * from users where id in (@ids)", {| ids = ids |})
return users |> Seq.map (fun u -> u.id, u) |> Map.ofSeq
})
// later in parallel code pieces
let! users =
userIds
|> Array.map (loader.GetAsync)
|> Async.Parallel // all parallel calls will be grouped into single batch call
How to make that work? When we're trying to call loader.GetAsync, several things have to happen:
- (Optional) If we use caching, we can check if we didn't have value for provided key already. In that case we can short-circuit it and return immediately. Otherwise...
- Add requested key to batch.
- Push notification to our synchronization context to enqueue current data loader. It will wait there until later async activation will step over code binding to
loader.GetAsyncreply and try to execute it. - Return a value from loader's internal
IVar(our promise). This value is async and it will wait until we call our batching function. It's important that we need to schedule it on our custom synchronization context. - Once
loader.GetAsyncwill get executed, an async activation will try to schedule the next (synchronous) step usingSynchronizationContext.Postmethod. There, we can override it and try to call our data loaders, which we enqueued on it in point 3. - We're going to dequeue loaders one by one and let them work sequentially - so that first needs to finish, before we start the next one. We trigger them by calling a custom
Commitmethod. It will internally replaceIVarand batch of current data loader with fresh ones (so they count as the next batch) and will call fetch function over all requested arguments grouped so far. - Once fetch function returns we complete our
IVar(causing all awaiting async activations awaiting at point 4 to continue) and communicate to our synchronization context (via customDonemethod) that it's safe to pick the next loader from the queue and repeat algorithm from point 6.
As you've might notice, the step through process is not quite easy to follow (eg. pt 7 wraps into 4 and 6), especially if we take into account, that not everything in there is called by our own code, but also by F# async state machine. There are many things that can go wrong here, and in that case all you'll see will be just an empty screen waiting in a deadlock. So better have a plan of action first!
We'll start from defining our DataLoader type:
type DataLoader<'id, 'value when 'id: comparison>(sync: DataLoaderContext, fetchFn: Set<'id> -> Async<Map<'id, 'value>>) as this =
let syncRoot = obj()
let mutable cache = Map.empty
let mutable batch = Set.empty
let mutable fetching = IVar.empty ()
member this.GetAsync(key: 'id): Async<'value> =
lock syncRoot (fun () ->
match cache.TryGetValue key with
| true, value -> value // 1. return cached async result if available
| false, _ ->
batch <- Set.add key batch // 2. batch key
sync.Enqueue this // 3. enqueue this data loader
let promise = fetching.Value
let value = async {
// 4. make this async work in our custom synchronization context
do! Async.SwitchToContext sync
// promise will return Map with `fetchFn` result for current `batch`
match! promise with
| Ok values -> return Map.find key (Result.unwrap result)
| Error err ->
// rethrow an exception preserving its stack trace
ExceptionDispatchInfo.Capture(err).Throw()
return Unchecked.defaultof<_> // never reached
}
cache <- Map.add key value cache
value)
Just like we mentioned, within GetAsync method we're executing steps 1-4 of our algorithm. What we didn't talk about, is that we require this operation to be thread safe. This time we'll fallback to good old lock function, since guaranteeing idempotency of this operation would be too expensive to use compare-and-swap.
Next, let's take a look at our modified synchronization context:
type DataLoaderContext() =
inherit SynchronizationContext()
let syncRoot = obj()
// currently executing data loader
let mutable atWork: ICommittable = null
let pending = Queue<ICommittable>()
let rec next () =
if isNull atWork && pending.TryDequeue(&atWork) then
atWork.Commit()
next ()
override this.Post(job: SendOrPostCallback, state: obj) =
job.Invoke(state)
this.TryCommitNext()
override this.Send(job, state) = this.Post(job, state)
member internal this.Enqueue(commit: ICommittable) =
pending.Enqueue commit
member internal this.Done() = lock syncRoot (fun () ->
// once current data loader is finished, we repeat the cycle
atWork <- null
next ())
member internal this.TryCommitNext() = lock syncRoot next
Here we're adding some internal methods used to communicate with our data loaders. Post method is called by F# async infrastructure and its role is to execute synchronous steps of our async code (discrete pieces in-between let! bindings generated by F# compiler). As part of this we check if no data loader (ICommittable object) is currently executing, and if not, picking next loader from the queue and commit it to do its work. Since we don't have control over when the Post is called, we also put it into synchronized block under lock guard.
So far, we skipped implementation of ICommittable to discuss rest of the infrastructure. It's really simple in its nature. What we do is to swap a contents of our DataLoader's IVar and batch to be sure they won't be altered while we're going to work with them. Next we call out fetch function over accumulated batch we retrieved and once it's complete, finish the IVar promise and inform synchronization context that the current data loader finished its work and the next one can be picked.
type DataLoader<'id, 'value when 'id: comparison> =
interface ICommittable with
member this.Commit() =
// swap the contents of batch and promise
let keys, ivar =
lock syncRoot (fun () ->
let ivar = fetching
fetching <- IVar.empty()
let keys = batch
batch <- Set.empty
(keys, ivar))
if Set.isEmpty keys then sync.Done()
else
Async.Start(async {
try
try
let! batchResult = fetchFn keys
ivar.Write (Ok batchResult) |> ignore
with e ->
ivar.Write (Error e) |> ignore
finally
// inform synchronization context, that current
// data loader finished its work
sync.Done ()
})
With these in our toolbelt, we're now ready to batch multiple independent requests and substitute them with one. This design can also work in nested manner, when subsequent parallel requests have their own dependencies that can be executed in parallel - you can see that in action here.
Summary
We presented a technique, that offers a way to mitigate N+1 Select negative performance footprint, by substituting multiple parallelizable requests with one. This approach is not perfect. We still may need to do a number of requests growing with a depth of our call tree - using example from above, we can optimize access to multiple users or orders, but since orders depend on users, we cannot parallelize them both at the same time, even thou we could write such query by hand.
What's even more interesting, this approach is not forced to work only with database queries. It can be generalized to pretty much any sort of parallel workloads, and help to write more optimal and more readable code by hiding the inner complexities of executing parallel code.
Comments